But now that I see some concerns about gender biases in big digital corpora, I do have a bit to say. Partly that I have seen nothing to make me think social prejudices played into the scanning decisions at all. Rather, Google Books, Hathi Trust, the Internet Archive, and all the other similar projects are pretty much representative of the state of academic libraries. (With strange exceptions, of course). You can choose where to vaccum, but not what gets sucked up the machine; likewise the companies.
I have, though, seen everything to make me think that libraries collections are spectacularly biased in who they collect. This is true of gender, it's true of professions, it's true of race, it's true of class. It's even true of the time in which an author write. I never get tired of thinking about this. Still, this doesn't bother me much. There are lots of interesting questions that can be successfully posed to library books despite their biases; there are quite a few than can be successfully posed because of their biases. The fact that a library chose to keep some books is not an inconvenient sample of some occluded truth; it's the central fact of what they, back then, just to let let us see. I deliberately say "their biases," and not "their selection biases:" I try never to talk of library collections as 'samples.' Sample implies a whole; I have no idea what that would be here. Would it be every book ever written? That would show extremely similar biases against the dispossessed. Not every word ever spoken; only some are permitted to speak. Even the thoughts of historical actors are constrained by what they are permitted to know.
We have to rest somewhere. In seeking the ideas bandied about in the past, the library is not only a good place to start, it is as a good a place to end as any. As for its biases; there is no getting around it; but there is understanding it. That's always been a core obligation of historians.
To come back to gender: those biases are a big reason why I like digital libraries. It's possible to get one's arms around the biases in the whole just a bit better; and since they resemble physical libraries so well, they tell us how we might have been misreading them. This applies to texts, but sometimes to their authors as well. Remember: we can only understand past actors insofar as they have attributes--gender, race, nationality--enumerated by the state, but it is those state categories in which we're so caught up today. (Perhaps to our detriment; maybe we should be looking for bias against aesthetes, or agnostics, or the victims of violence). It's only rarely possible to escape those categories even a bit to see around the big issues. Tim Sherratt's now-canonical example of faces does it for real individuals. But in the aggregates, I think there's something about names. Names can tell us about gender; but they can also take us outside it.
A couple weeks ago, I downloaded the 1% IPUMS sample of 1910 and 1920 US census records. Those years, unlike many others, have names for each record. I already have author names as well, from the Open Library. It's Downton Abbey all over again: I can just divide between the two sets to see what names are used too little, and what names too much. I could guess at a headline figure on the gender breakdown of books in libraries; something like 10% of books are by women before 1922, maybe, but let's not reduce so far yet. Let's stay with the names. If more than 50% of the holders are women, call it a female name, and vice versa.
How do these names stack up? The numbers will not surprise you, but it's worth putting them down because we don't really know this about our libraries, I don't think, and we clearly want to:

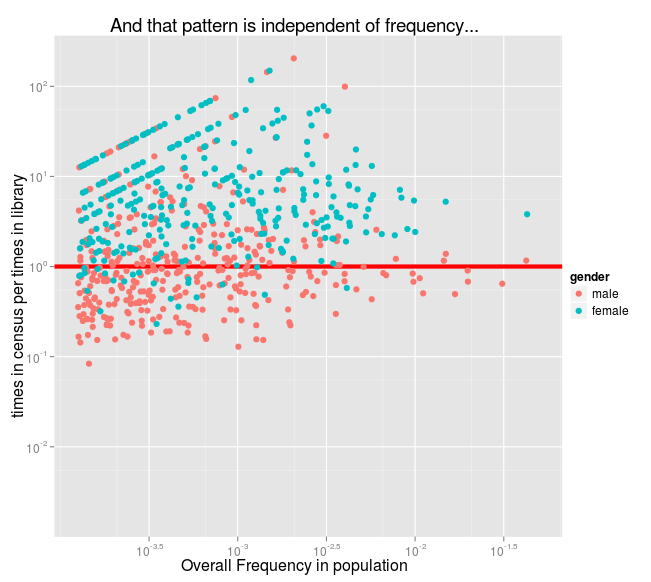
That red line at 10^0 (ie, 1) is where a name is equally frequent in the US census, and in the Open Library list of authors. 10^1 is ten times as frequent in real life, 10^-1 is ten times as frequent in books, and so on. So the most men's names are at about 2x more common in books than in the census, and the peak of the women's names fall somewhere between 8x less common and just slightly more.
And remember, each of those distributions is built up of individual names. Let's make them dots at first. Here I've arranged each first name from left to right by overall frequency: you can still see the differing patterns of women's names, usually about 9x more common in the census, and men's names, usually about 2x as common in libraries.
But there's no story to dots. Split up the genders and see the names themselves, and you get something we can talk about.

It is hard not to conflate the names to classes of people. Mary, the eldest daughter, the most common name in the country, is about 4x more common in real life than on book title pages. Annas do worse; Graces do better. Who are those pioneers below the line: Amy, Sara, Eleanor, and Anne? Despite all odds, they are more common among authors than among women. Clearly the census taker mostly just wrote down "Francis" for Frances before asking the gender dozens of times; but could there be a bigger story, too, about female Francis's better able to push through the doors of print.
And for the men. Why is John so different from William and George? How many of those over-represented single letters, which are usually men in the census, are actually women in disguise (GEM Anscombe, JK Rowling) in the libraries? Are those Willies all boys, those Joes all men?
I find it easy to spin out stories here about access to publishing that may or may not be true: about predominantly wealthy Eleanors allowed to write novels, about poor Irish Michaels who never finished school, about rich Yankee Williams and hardscrabble, farming Johns. It would be easy to test some of these stories, harder to test others. But we could always start.
We may not care about names. But for the questions we do care about, the ones that the state has been codifying and enumerating since it came of age, the questions are even easier to answer, because that's what they've been collecting on. I suspect that the solution lies in what we already have.
Great post as always; I've been hoping somebody would tackle the issue of "bias" explicitly. Unfortunately, to your point about samples and selections, the collection *is* a selection out of some sample. What it is sampling from may be amorphous and could change depending on question and circumstance, but it is an explicit selection with some biases nonetheless.
ReplyDeleteThe problems come when teasing apart the sample from whatever you implicitly assume the selection comes from. In this case, you suggest that there may be a story about some sort of barrier-to-publication bias, as with Francis or Eleanor. That's an implicit assumption that the selection process of the library takes second seat to the selection process of publication in the case of choosing who to allow through the gates. It's not necessarily a bad assumption, but it's one that should be clear. It's also one that assumes there are only two factors contributing to the gendered effect we see: perceived gender of author by publisher, and perceived gender of author by librarian.
I think it's very important to show the salient, upper-level features of a dataset in the way that you are doing, but I also think it's important to explicitly state that the visible features are built atop an entire architecture of possible selection biases. Otherwise, it becomes very easy to accidentally assume the underlying data being collected are normally distributed around the middle.
For example, say, 60% of published authors are men, so we assume publishers don't choose women as much. It could be that 100% of the pool of women who submit manuscripts get accepted, but women submit much more infrequently, for whatever other reasons, so they still comprise only 40% of the dataset.
It doesn't really matter what the data are sampled from, but based on a question (were women chosen less frequently by publishers?) we need to have some sense of the underlying distribution (how many women submitted vs. men?) before we can draw meaningful conclusions.
I've been trying to visually map many of the important factors which might affect this sort of thing for history research - a very rough/incomplete pass found here: http://www.scottbot.net/HIAL/wp-content/uploads/2011/10/diagramBold.png - with the idea eventually being to create some statistical hierarchical model drawing from data like what you extracted in this post.
Thanks, Scott. To be clear, I don't think library selection based on perception of gender (or publisher selection on the same, which is what I think I was implying w/ Francis--it's hard to tell even for me) is the most important selection criteria. There is almost certainly no way to know what that is (a pretty important qualification), but I'd suspect it's who gets encouraged in their plans to write a book, and who does not.
DeleteA while ago I started to write down all the various different filters that exist for this particular data aset. I got this far:
What people want to write
(Filtered by literacy, access to writing technology, fear of censorship, other forms of superego regulation, etc.)
What people actually write
~~~
What people want to publish
(Filtered by the wish to have more than one copy)
What gets published
First big gatekeeping group is contemporary publishers. And then republication,too.
What gets acquired by libraries
~~~
What libraries don't lose
~~~
What scanning partners scanned
~~~
What scanning partners released publicly
1922!
What the data analyst kept
~~~
There is selection against most groups in society in each stage here. Add some more levels in, and we'd start to get close; each level can be characterized as a biased sample of some point of a higher one. But I don't think the fundamental truth of library is as an imperfect sample of one of these higher levels. (If all those Billies are little boys, is the library really an imperfect sample because it doesn't save their books?).
So to your point about samples: it is a sample of lots of things; but I still try to avoid talking about it that way, because leads us down a pretty hopeless road of trying to recreate an original whole. The only thing any historian or literary scholar has ever done is describe some imperfectly formed corner of texts; I don't think that using computers to do so carries an obligation to suddenly start describing the whole of culture. (Not that you're saying that, of course).
I think actually quantifying the biases at each of these levels, though, is going to be extraordinarily difficult, since we know almost nothing about most authors besides their names and birth dates. In some cases, that's enough to link them to a census, but in most, it won't be. And even if we had a census record for every author, we wouldn't know really much about them to describe all their biases. Can I write about Darwin without explicitly noting whether the authors in libraries are more or less religious than the general population?
I don't know, I'm still rambling here. Sometime I may get my thoughts straight on this.
Thanks for the reply; thinking about this in "filters" is probably a good way to go about it. As you say, I'm not suggesting we need to start describing the whole of culture, but I think by looking at data from different stages in the filtration, we can use hierarchical statistical models to infer probabilistic boundaries around the biases. So, while this isn't explicitly "quantifying the bias," we can still get closer to finding the range of bias values that seem reasonable, given our limited knowledge of various filters. This may fill in the surrounding ecosystem of bias enough that we could start talking quantitatively about the bias of a particular dataset, given necessarily incomplete knowledge.
ReplyDeleteThat sort of (locally) surrounding knowledge isn't necessary in all (most) situations, but I think it will allow us to answer a lot of interesting questions we wouldn't have otherwise been able to.
I would have expected to see Mary and John below the line: I probably overestimated the amount of Christian lit and scriptural references in your corpus. But all the biblical names at the fore of the female-name frequency (Sarah, Elizabeth, Anna, Ruth, Martha) show a sign of indirect textual influence, which is kind of fun. Although I'm sure somebody's worked on naming practices and has a lot to say about this.
ReplyDelete@Scott: Yeah, I find the idea that we can use probabilistic models to start quantifying biases really interesting. I guess possibly I'd think that what's really interesting is not that we get to talk about our datasets differently, but that we get to really understand the filters: because each filter applied is a really important application of power. But that's pretty much the same thing.
ReplyDelete@Jamie: Just to be clear; this is the first names _of authors_ taken from the metadata, not first names used in the texts. (That would be interesting too, though--I think I took one pass at it once and confirmed that, yes, there are _way_ too many Jacks in books.)
I am just catching up with this post, but since comments are still open even a month later...
ReplyDeleteI wonder how geography factors into this. Can you get location information for these datasets? If, for example, libraries in New England did a disproportionate amount of collecting among all libraries in the US*, and if a disproportionate amount of what they collected came from within their region, and if names in the census were not distributed evenly throughout the country, what effect did this have on the distribution of names in library collections? That's a lot of ifs, but it seems like an interesting path to pursue if there's enough data to get at it.
*I'm just making this up, but it sounds plausible, given the strength of both the public library movement and academic libraries in the region.
I know that the major sources for this text collection are the university libraries Michigan, California, and Harvard, so I bet the major hole in that direction is the South--which probably does have it's own names. (That could be the Johns, actually, too). Publishing locations are overwhelmingly in the Northeast.
DeleteThe census data is well localized, so state-by-state analysis would definitely be possible. As well as telling if those California books are actually only held by the UC libraries.
On public library data, this could be really interesting--we can know from catalog information alone where a book was published, its author's first name, last name, the location of the library itself--this would be a fun thing to look at when the DPLA APIs get some more data to work with.