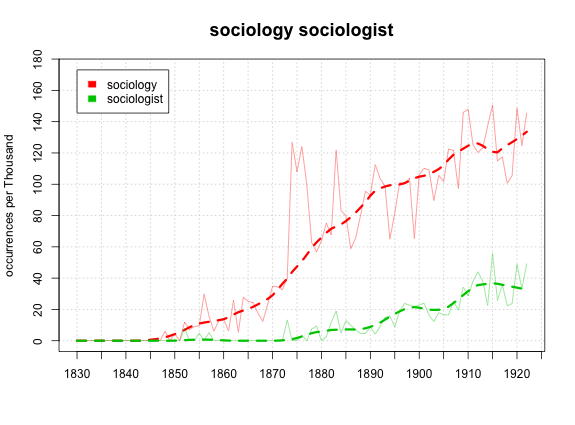
And Darwin after the break.
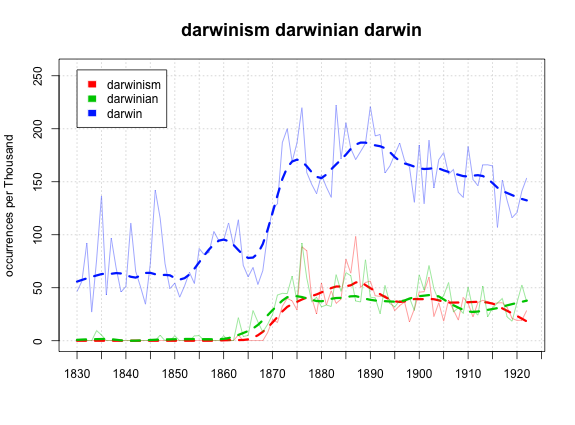
In both these cases, we have a lead word that captures most of the movement, and then one or two follower words below that check in decade later and then fairly well track the main word's movement. I'd have to plot them normalized to be sure, but I think my similarity functions would notice the similar curves here. The only worry I have is that "Darwin" has a baseline of about 50, which might make the function think that it's very different from the derived adjectives. (It is different, of course, but short of running a script to get the data for "Charles Darwin", which I remain loathe to do, there's no way to exclude the references in there to Erasmus, the Australian city, etc.).
Good stuff, Ben. I want "Darwinist," for the record, on the last one. Any chance? Also, any way to tell whether things like "Darwinism" are getting mention more in natural-sciences works or elsewhere? Maybe by finding linked words (before you get your "genre" thing up and running)?
ReplyDeleteBeen meaning to comment--"darwinist" is very rare, and didn't make my initial cut. There are 3922 occurrences of 'darwinism' in the data set, and just 84 of 'darwinist' and 'darwinists' combined. So whatever the numbers are, they're going to be tiny compared to the others. (I'd put them up, but I have to fix a few things in the database before it works again.)
ReplyDelete