I did a slightly deeper dive into data about the salaries by college majors while working on my new Atlantic article on the humanities crisis. As I say there, the quality of data about salaries by college major has improved dramatically in the last 8 years. I linked to others' analysis of the ACS data rather than run my own, but I did some preliminary exploration of salary stuff that may be useful to see.
That all this salary data exists is, in certain ways, a bad thing--it reflects the ongoing drive to view college majors purely through return on income, without even a halfhearted attempt to make the results valid. (Randomly assign students into college majors and look at their incomes, and we'd be talking; but it's flabbergasting that anyone thinks that business majors often make more than English majors because their education prepared them to, rather than that the people who major in business, you know, care more about money than English majors do.
Thursday, August 23, 2018
Friday, July 27, 2018
Mea culpa: there *is* a crisis in the humanities
NOTE 8/23: I've written a more thoughtful version of this argument for the Atlantic. They're not the same, but if you only read one piece, you should read that one.
Back in 2013, I wrote a few blog post arguing that the media was hyperventilating about a "crisis" in the humanities, when, in fact, the long term trends were not especially alarming. I made two claims them: 1. The biggest drop in humanities degrees relative to other degrees in the last 50 years happened between 1970 and 1985, and were steady from 1985 to 2011; as a proportion of the population, humanities majors exploded. 2) The entirety of the long term decline from 1950 to 2010 had to do with the changing majors of women, while men's humanities interest did not change.
I drew two inference from this. The first was: don't panic, because the long-term state of the humanities is fairly stable. Second: since degrees were steady between 1985 and 2005, it's extremely unlikely that changes in those years are responsible for driving students away. So stop complaining about "postmodernism," or African-American studies: the consolidation of those fields actually coincided with a long period of stability.
I stand by the second point. The first, though, can change with new information. I've been watching the data for the last five years to see whether things really are especially catastrophic for humanities majors. I tried to hedge my bets at the time:
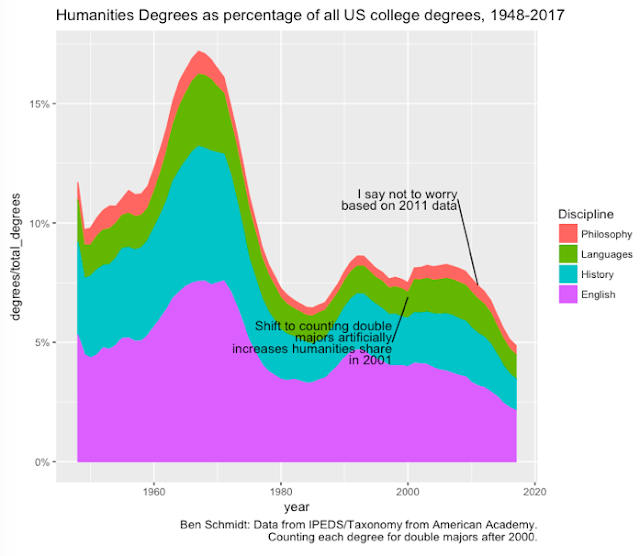
Back in 2013, I wrote a few blog post arguing that the media was hyperventilating about a "crisis" in the humanities, when, in fact, the long term trends were not especially alarming. I made two claims them: 1. The biggest drop in humanities degrees relative to other degrees in the last 50 years happened between 1970 and 1985, and were steady from 1985 to 2011; as a proportion of the population, humanities majors exploded. 2) The entirety of the long term decline from 1950 to 2010 had to do with the changing majors of women, while men's humanities interest did not change.
I drew two inference from this. The first was: don't panic, because the long-term state of the humanities is fairly stable. Second: since degrees were steady between 1985 and 2005, it's extremely unlikely that changes in those years are responsible for driving students away. So stop complaining about "postmodernism," or African-American studies: the consolidation of those fields actually coincided with a long period of stability.
I stand by the second point. The first, though, can change with new information. I've been watching the data for the last five years to see whether things really are especially catastrophic for humanities majors. I tried to hedge my bets at the time:
It seems totally possible to me that the OECD-wide employment crisis for 20-somethings has caused a drop in humanities degrees. But it's also very hard to prove: degrees take four years, and the numbers aren't yet out for the students that entered college after 2008.But I may not have hedged it enough. The last five years have been brutal for almost every major in the humanities--it's no longer reasonable to speculate that we are fluctuating around a long term average. So at this point, I want to explain why I am now much more pessimistic about the state of humanities majors than I was five years ago. I'll show a few charts, but here's the one that most inflects my thinking.

Tuesday, July 10, 2018
Google Books and the open web.
Historians generally acknowledge that both undergraduate and graduate methods training need to teach students how to navigate and understand online searches. See, for example, this recent article in Perspectives. Google Books is the most important online resource for full-text search; we should have some idea what's in it.
A few years ago, I felt I had some general sense of what was in the Books search engine and how it works. That sense is diminishing as things change more and more. I used to think I had a sense of how search engines work: you put in some words or phrases, and a computer traverses a sorted index to find instances of the word or phrase you entered; it then returns the documents with the highest share of those words, possibly weighted by something like TF-IDF.
Nowadays it's far more complicated than that. This post is just some notes on my trying to figure out one strange Google result, and what it says about how things get returned.
A few years ago, I felt I had some general sense of what was in the Books search engine and how it works. That sense is diminishing as things change more and more. I used to think I had a sense of how search engines work: you put in some words or phrases, and a computer traverses a sorted index to find instances of the word or phrase you entered; it then returns the documents with the highest share of those words, possibly weighted by something like TF-IDF.
Nowadays it's far more complicated than that. This post is just some notes on my trying to figure out one strange Google result, and what it says about how things get returned.
Wednesday, June 13, 2018
Meaning chains with word embeddings
Matthew Lincoln recently put up a Twitter bot that walks through chains of historical artwork by vector space similarity. https://twitter.com/matthewdlincoln/status/1003690836150792192.
The idea comes from a Google project looking at paths that traverse similar paintings.
This reminds that I'd meaning for a while to do something similar with words in an embedding space. Word embeddings and image embeddings are, more or less, equivalent; so the same sorts of methods will work on both. There are--and will continue to be!--lots of interesting ways to bring strategies from convoluational image representations to language models, and vice versa. At first I though I could just drop Lincoln's code onto a word2vec model, but the paths it finds tend to oscillate around in the high dimensional space more than I'd like. So instead I coded up a new, divide and conquer strategy using the Google News corpus. Here's how it works.
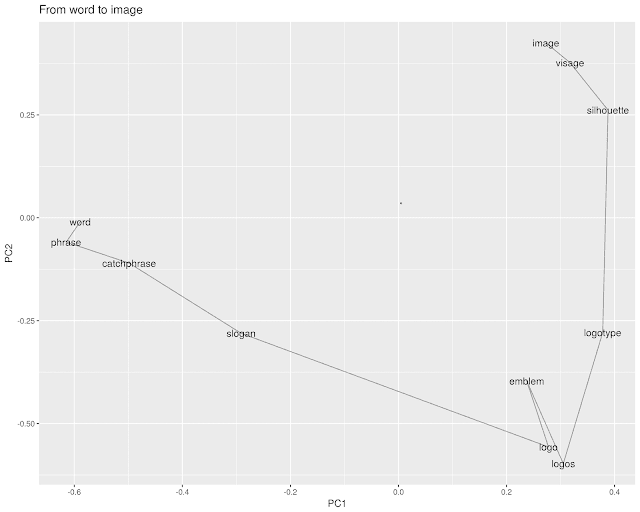
The idea comes from a Google project looking at paths that traverse similar paintings.
This reminds that I'd meaning for a while to do something similar with words in an embedding space. Word embeddings and image embeddings are, more or less, equivalent; so the same sorts of methods will work on both. There are--and will continue to be!--lots of interesting ways to bring strategies from convoluational image representations to language models, and vice versa. At first I though I could just drop Lincoln's code onto a word2vec model, but the paths it finds tend to oscillate around in the high dimensional space more than I'd like. So instead I coded up a new, divide and conquer strategy using the Google News corpus. Here's how it works.

Subscribe to:
Posts (Atom)