Some of the theories are deeply interesting. I really like the censorship stuff. That really does deal with books specifically, not 'culture,' so it makes a lot of sense to do with this dataset. The stuff about half-lives for celebrity fame and particularly for years is cool, although without strict genre controls and a little more context I'm not sure what it actually says--it might be something as elegaic as the article's "We are forgetting our past faster with each passing year," but there are certainly more prosaic explanations. (Say: 1) footnotes are getting more and more common, and 2) footnotes generally cite more recent years than does main text. I think that might cover all the bases, too.) Yes, the big ideas, at least the ones I feel qualified to assess, are a little fuzzier—it's hard to tell what to do with the concluding description of wordcounts as "a great cache of bones from which to reconstruct the skeleton of a new science," aside from marveling at the
But it's the methods that should be more exciting for people following this. Google remains ahead of the curve in terms of both metadata and OCR, which are the stuff of which digital humanities is made. What does the Science team get?
It shows how far we're coming on some of the old problems of the digital humanities. Natalie asked in the comments and on her blog about whether OCR was good enough for this kind of work. Well, the OCR on this corpus seems great. It makes me want Google to start giving Internet Archive-style access to their full-text files on public-domain books even more. To take a simple example: my corpus of 25,000 books with Internet Archive OCR has about 0.3% as many occurrences of 'tlie' as 'the'. Ngrams has more like 0.025% (division not included). Putting together all the common typos, that's something like one in a thousand errors instead one in a hundred. (Although I wonder why they Google doesn't run some data cleanup on their internal internal OCR; it's pretty easy to contextually correct some common 'tli's to 'th's, etc.) That might already be at the level natural language processing becomes feasible. They did filter the texts to keep only ones with good OCR. But that's OK: it makes it easier to target the bad ones now that this team apparently has a good algorithm for identifying what they are.
They get some pretty impressive results, too, out of the Google metadata. (Or as I like to call it, the secret Google metadata.) The researchers purged a lot of entries using the awesomely named "serial killer algorithm." Despite its name and the protestations of the methodological supplement (pdf, maybe firewalled?), it doesn't look like it just eliminates magazines; by dropping out entries with no author, for example, it's probably just clearing out a lot of entries with bad metadata. (The part of the algorithm that cuts out based on authors takes out more than 10 times the one that looks for publication info in the title field. BTW, they claim to have an appendix that describes the algorithm, but I can't find it on the Science site—any help?) The net results of the metadata filtering seems to have worked quite well; the ngrams results for "Soviet Union" in the 19th century look better than the Google Books results. Using errors in Google books is not a fair way to criticize ngrams. There are ways to break it, of course, and maybe I'll play some more with that later. But it's not bad.
There are certainly problems with their catalogue. They estimate that either 5.8% or 6.2%—pages 5–6 of the supplement are internally inconsistent—of their books are off by five or more years, and don't provide the figure for percentage of books off by at least one year. The fact that language was miscategorized in 8% of books makes it questionable how good genre data would be, were Google to include. That and the BISAC problem make me wonder if serious large-scale humanities research isn't really going to use HathiTrust, even if their corpus is significantly smaller.
But my mantra about digital history has always been: No one is in a position to be holier-than-thou about metadata. We all live in a sub-development of glass houses. That applies to pen-and-paper historians as much as it does to digital ones: If you've ever spent any time looking at archival files or oral histories, you've seen dozens of casual misdatings of letters and events that can be impossible to resolve. And if you've spent more than a day, you've certainly been tricked by one or two. The paper is perhaps not forthcoming enough about the failings (although Googler Orwant certainly has elsewhere), but compared to what I'm working with, at least, they can be somewhat proud of themselves.
And the math is pretty neat. It's great to see the law of large numbers in effect on these textual corpora--I'm against the three-year smoothing, which most people don't seem to realize is going on, but the efforts to apply similar patterns to large lists of people from wikipedia is great. Things like standard half-life curves for fame are good as a way of testing claims of remarkableness, although using them to produce lists for future research is probably premature.
Also--one thing I've found in looking at my own data is that for a lot of things we're interested in, the percentages of books that contain a word we want are at least as illustrative as the percentage of words. They capture different aspect of the use/mention spectrum, in some way: Example (using my data, not ngrams), with wordcounts:

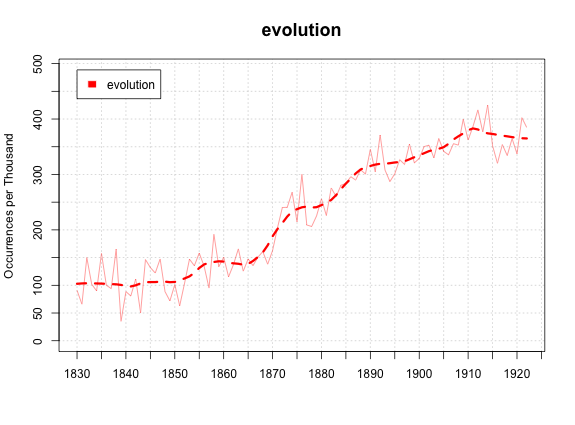
The difference, though, illustrates the most important thing about this data: there's no one right way to read it. Wordcounts give us millions of data points in hundreds of thousands of dimensions to compare against each other. It's up to researchers to figure out how to get those abstract forms projected into a two dimensional image that actually tells us something. But it will never tell us everything, not even close. Looking at the computer screens, we're all in Plato's cave. Except, maybe, when we actually read the books.
No comments:
Post a Comment