So as interesting as Google Ngrams is for all sorts of purposes, it seems it might always end right in 2008. (I could have sworn the 2012 update included through 2011 in some collections; but all seem to end in 2008 now.)
Lo: the Ngram chart of three major publishers, showing the percentage of times each is mentioned compared to all other words in the corpus:
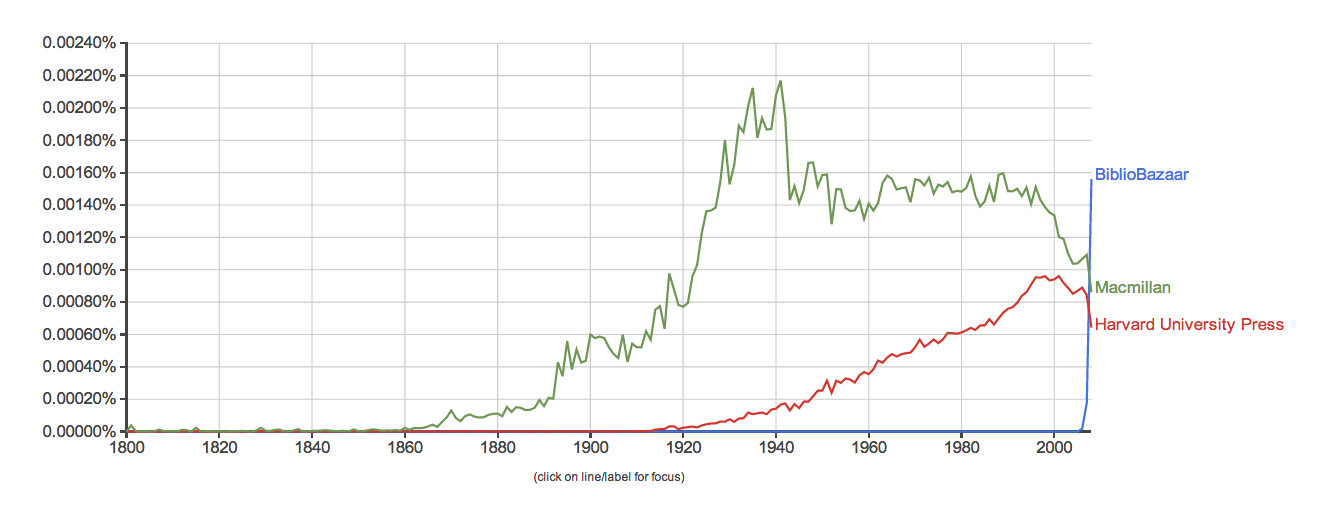
This, if anything, massively understates the importance of BiblioBazaar to Google Books in 2008: using the 2009 data, here's the percentage of all books (rather than words) mentioning each of those three presses:
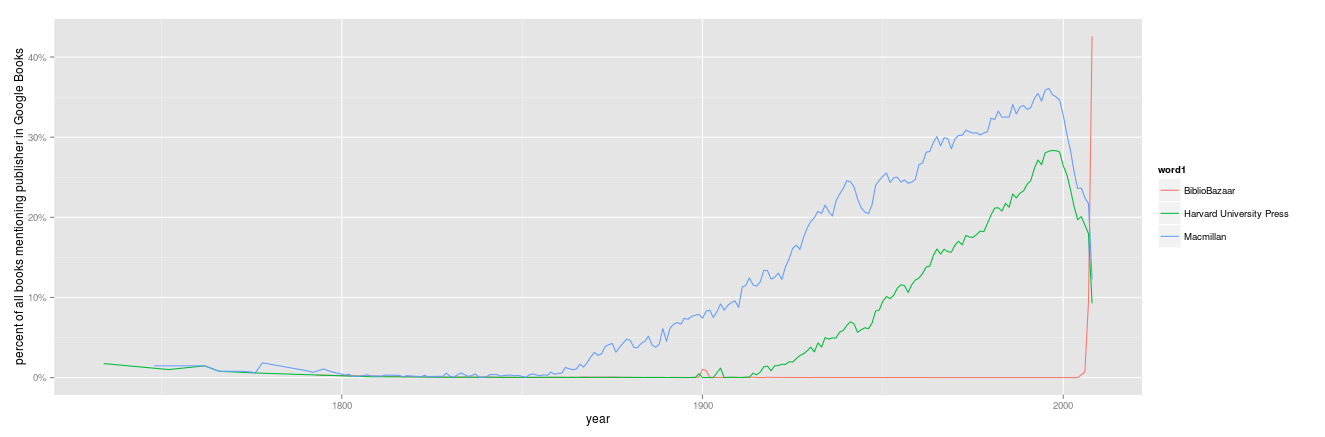
This doesn't mean that 35% of all the books in 2000 are Macmillan, because other books will cite Macmillan in footnotes. I bet almost every university press book in the humanities and social sciences cites Harvard University Press in 1999. But given that BiblioBazaar barely existed before 2008, hardly any non-BiblioBazaar books would mention the company in 2008. So apparently, BiblioBazaar is almost 45% of the 2008 sample in Google Ngrams. That's incredible.
How did "BiblioBazaar" supplant the largest presses in just one year?
This has messed up other sources: Publisher's Weekly reported in 2010 on how BiblioBazaar leapt to the top of the Bowker's charts. In that, the company's president is asked if they really published 270,000 books in 2009:
"If by ‘produce' you mean create a cover file that will print at multiple POD vendors, a book block that will print at multiple POD vendors, and metadata to sell that book in global sales channels, then yes, we did produce that many titles," said Mitchell Davis, president of BiblioLife, parent company of BiblioBazaar.And what sort of books are they?
All of the company's content is in the public domain, and are basically "historical reprints," Davistold PW, with foreign language books, and their "added layers of complexity" the fastest growing category of books. "Dealing with out-of-copyright materials lets us leverage our knowledge and relationships in the global bookselling industry more easily as we build out what is shaping up to be a pretty killer platform," he noted.In other words, the entire 19th century sprang back into print. You can see this in the Ngrams charts pretty clearly: "thou","thee", and"thy," for example, shoot up fivefold in 2007-2008 after centuries of decline. I've noticed this before, but now I'm inclined to think most of it can be attributed to this one company.
Or "railway." This isn't qualitatively different from other shifts in the Ngrams database: the gaps at 1922 as the library composition shifts, for example. But it is quantitatively of a different order. The complete immateriality of books post-2008 means that minor decisions about whether an e-book actually exists or not can cause shifts in 40% of the corpus. I spent some time looking for words that shift at the 1922 break, and though they do exist (it seems that the loss of Harvard drops most medical terms, for example), the shifts are a few percentage points: nothing that anyone should be taking seriously in that noisy a dataset anyway. But half the corpus: that's something else entirely.
Among other strange things, that means Ngrams is almost certainly at its most useful right now; with each year, it gets further and further out of date, and it will be extremely hard to update it without making a lot of extremely hard choices.
Quick postlude: I should hasten to say that everyone involved with Ngrams is aware of all the class of problems like this, and that the quick credibility-check for anyone citing Ngrams is that they don't use the post-2000 books as any sort of evidence. There's a reason the default settings stop in 2000, and that the Michel et al paper urges you not to use the newer data. But I hadn't realized before how different 2008 was, in particular.
Wow. I knew they were an enormous problem, but I hadn't come close to understanding the scale of the challenge they pose.
ReplyDeleteAs bad as their polluting the data may be, there's an even more worrisome element of their business model. The parent company partnered with libraries, offering to scan their pre-1923 titles for free in exchange for digital copies. (It's been alleged that another publisher, Kessinger Press, was simply downloading the Google scans and repackaging them. BiblioBazaar says that's not what it's doing. I have no way to evaluate that claim.)
What's fascinating to me is that these BiblioBazaar editions of public domain works are not available to be read on Google Books. Not as full books. Not as limited numbers of pages. Not even as text snippets. They're simply blank. If you want them, you'll have to buy them as print-on-demand editions off Amazon or another seller. Now, why should that be?
Let me offer another general and vague observation. Quite often, when there's a BiblioBazaar edition of a work, I can't seem to find a fully accessible version on Google Books. And in a few cases, I've been using a scanned pre-1923 edition of a work in research, and returned to find it no longer accessible, and noticed that there is now a BiblioBazaar edition.
That's not dispositive. Google Books is screwy in a lot of ways. But there's a track record of other publishers - most notably Kensington - allegedly filing fraudulent reports of copyright violations with Google, using its automatic processes to remove full-text editions of public domain works from Google Books. That leaves only the expensive print-on-demand editions for many titles.
So when I see a shady publisher slapping modern copyright dates on public domain works, and preventing anyone from seeing even snippets of the texts, I get very worried and very suspicious.
That's totally fascinating, and--as you say--far more important than whatever it does to the data sets. I've only hit the minor but consistent inconvenience that the reprints show up at the top of the searches, but what you lay out seems completely plausible. Unlike YouTube infringements, which use the same basic principle, there's no agent out there with any interest in keeping a book online besides Google itself.
DeleteIn theory, most of those removed public-domain works should stay in Hathi and the Internet archive, which have a lot of the Google scans; I wonder if there's some way to see how big the problem is by looking for books in the Hathi catalogue that have been removed from Google. I suspect not, because bulk access to the Google catalogue is really difficult.
If ever there was a case for making sure we understand our sources and data, you just made it. Very cool.
ReplyDeleteI don't suppose this makes n-grams obsolete. Maybe it's just an opportunity to acknowledge that what we really want in the datasets is first editions only. Unless we're using the corpus for another reason. In which case we might not. It comes down to control over what's in or what's out though. And at the moment we really don't have that.
ReplyDeleteYes, precise control of contents is incredibly useful; we (ie, Erez Aiden's lab at Rice, which prompted Google to build the Ngram browser to begin with) and myself) have a joint proposal in at the NEH with the Hathi Trust Research Center for a Bookworm browser that would enable all sorts of custom corpora creation based on metadata.
DeleteBut one of the things that's most interesting about Google Ngrams is that it showed you can get a remarkably usable dataset by simply outsourcing the decisions about whether to include a book or not based on the fact of publication. (And a few other things—language and OCR quality, in particular).
And that paradigm, at least, is breaking down. You could say that actually, Ngrams only works through 2000 because human librarians (alive and dead) chose which books would be counted; and that at the moment it switched to publishers supplying the books, something changed. That seems possible.
"what we really want in the datasets is first editions only. Unless we're using the corpus for another reason"
DeleteI'm not so sure about that. It betrays a certain assumption about our data use, which is that we assume ngrams-by-publication-date are a good proxy for measuring *something* culturally relevant. More specifically, that what words are written in any given year represent or are correlated to some cultural signal.
But (as Ben and others have brought up before) the dataset isn't a universal sample, it's representative of a human (in this case mostly librarian-driven) selection process. Thus, the sample isn't necessarily one of what is written, but what is read or saved or kept for whatever reason. That selection process changes with a publisher-driven model, but it doesn't necessarily take it any closer or farther from the original assumption.
Which is all to say, the ideal sample existed no more before 2000 than after, and it's something I haven't really seen confronted in studies that rely on these analyses. The creation process for the corpora fluctuate. I'm sure more recent books, even pre-2000, are less reliant on their popularity to have made it into ngrams than books from 300 years ago. The earlier we go, though, the less Adam's basic claim (1st published edition is meaningful because it's about first word use) holds up to scrutiny.
What's needed, and hopefully can come out of this new project Ben mentioned, is a serious study of what exactly the signal is being processed. Is it a study of what's being written, of what's being read, of what's being saved? Only then can we start saying things like "all we want are the first published edition."
On a different level, this has made it remarkably difficult to find authentic old books. A search on Bookfinder et al. will typically only reveal an avalanche of POD junk.
ReplyDelete