It's interesting to look, as I did at my last post, at the plot structure of typical episodes of a TV show as derived through topic models. But while it may help in understanding individual TV shows, the method also shows some promise on a more ambitious goal: understanding the general structural elements that most TV shows and movies draw from. TV and movies scripts are carefully crafted structures: I wrote earlier about how the Simpsons moves away from the school after its first few minutes, for example, and with this larger corpus even individual words frequently show a strong bias towards the front or end of scripts. These crafting shows up in the ways language is distributed through them in time.
So that's what I'm going to do here: make some general observations about the ways that scripts shift thematically. In its own, this stuff is pretty interesting--when I first started analyzing the set, I thought it might an end in itself. But it turns out that by combining those thematic scripts with the topic models, it's possible to do something I find really fascinating, and a little mysterious: you can sketch out, derived from the tens of thousands of hours of dialogue in the corpus, what you could literally call a plot "arc" through multidimensional space.
Words in screen time
First, let's lay the groundwork. Many, many individual words show strong trends towards the beginning or end of scripts. In fact, plotting movies in what I'm calling "screen time" usually has a much more recognizable signature than plotting things in the "historic time" you can explore yourself in the movie bookworm. So what I've done is cut every script there into "twelfths" of a movie or TV show; the charts here show the course of an episode or movie from the first minute at the left to the last one at the right. For example: the phrase "love you" (as in, mostly, "I love you") is most frequent towards the end of movies or TV shows: characters in movies are almost three times more likely to profess their love in the last scene of a movie than in the first.

(I'm including TV shows and "unknown" as a sanity check. The same pattern holds for television; but movies tend to be more romantic.) That love waits for the end to declare itself is not necessarily surprising: but it is fundamental to the medium, and a phenomenon well worth understanding better. What other conventions are there like this? How do individual TV shows play off these shared structural elements of the medium as a whole?
Lots of individual words or phrases have their own trends, even ones that don't map so firmly to our understanding of plot points. Take the phrase "if you," for instance. It's rare at the beginning of scripts, common in the middle, and then rare again towards the end. Why? Well, presumably it encapsulates a particular type of dialogue, in which the protagonist has to give or seek advice about the consequences of their actions. First scenes won't have the necessary exposition laid out for the hero to reach a crossroads; and as the script wraps up in the third act, the importance of decisions fade out in favor of consequences. You can see them working through those results grammatically, as well: the word "because" (not shown) becomes more and more common as the typical script proceeds.

These are interesting, and at some point I'll share a link for exploring these words on your own. I could probably go on for quite a while. But right now, though, my question is less about the individual instances than about generalizing some of the patterns underlying these shifts.
One way to approach these overall questions of structure would be to use all the words in the scripts, and search for interesting patterns. This is actually feasible, though computationally pretty difficult, and something I'll keep in mind for later. But for now, the topic models I described last time provide a nice way to understand what's actually going in a typical plot arc. (If you're new here and don't know what topic models or LDA are, all the digital humanists got together and decided that this post by Ted Underwood is the one to read for an explanation.)
Topics in screen time
Just as words show patterns in screen time, so do topics. But since I only have 127 topics, it's easy to search all of them for the strongest patterns. Using linear models to test fittedness to a straight line, I went through the data set to pull out the nine topics that show the strongest directionality. Here they are (click to enlarge):

All of these topics show clear and strong directionality. Over the course of a script, characters talk more about the truth and lying; they more often narrate murders; they use the language of apology and authenticity. (Two out of the nine topics display "sorry" prominently.) They talk less, on the other hand, about "business" and "companies," about their "job" and the "office," and about times of day.
Using the same method but working from the middle out, I can also see which topics are clustered in the middle of episodes or movies; or conversely, which ones are predominantly used in the beginning or ends of scripts. Some of these curves aren't quite as pretty, but do show the elements that tend to get dropped or emphasized when the game is actually afoot. The two topics used mostly at the edges are grand language about the world and the government: there are some really beautiful curves that show up mostly in the middle of movies. Two pairs in particular stick out. One pair is "look eyes face Look eye" and "hand head cut hands," suggesting that focuses on the human body and the human face occur mostly in the heart of films. The other is "question answer questions" and "talk doesn people wants says," suggesting that descriptive language about narration or questioning also is comparatively rare in the first and third acts.

It's easy to get a little just-so about these curves. For instance, after falling away later, the face does return in last scenes, Does the face return, in ways that the rest of the body doesn't, because it contains the same grand eternal resonance that the nation and the world can have? Maybe that's crazy. But certainly, there are major elements of structural similarity being shown by these patterns.
[One caveat before I get into the really exciting stuff: the way I've chosen to arrange the data is creating a few odd artifacts here. In particular, dividing up into three minute chunks and then dividing into twelfths occasionally does strange things. This is particularly true for shows shorter than 24 minutes, which typically end lacking any three-minute chunks assigned to twelfth 2, 3, or 4. (I think). In later versions I may change this; but it could take a few days of on-again-off-again computation, and I'm so interested in these models right now I don't want to take the time off.]
Moving through topic space in screen time
So: those charts show the distribution of topics in screen time. I think that's a practice less susceptible to embarrassing errors than one I've objected about in the past, of plotting topics in historical time, because the guarantee that each author is equally represented across time periods helps to eliminate some questions of linguistic drift. (There are other problems, though: I'm sure that having about 200 documents that all say "Space: the final frontier" in their first couple minutes is skewing certain elements of the model in odd ways).
I'm not interested, fundamentally, in topics, though: I'm interested in the TV shows. So how can we move from writing about topics, which is boring, to writing about television, which isn't? The answer is: we think about the ways that individual episodes of TV shows move through the space created by topics. One way to do that is through dimensional reducing the topic space using principal components analysis. Let me ease into that, though, by using just a few of the topics to explain.
Suppose we take what I think is the most interesting linear trend above; the shift from the mundane world of talking about times of day to the personal world of giving and taking apologies.

This chart is showing proportion of the morning-tomorrow topic on the y axis, and of the sorry-really-talk topic on the x axis. A typical script starts in part 0, using 1% "apology" language and 1.6% "time" language. By the end, those proportions have been flipped: that script moves from one pole to the other.
We don't just have to worry about a "typical" script, though: we can drop any text we want into this same space and see how it moves. These tend to be noisier because of the smaller sample, so I'm going to use 6 parts rather than 12. (If I really wanted to dazzle you, I'd use a moving average that would artificially smooth the curves: but that's not totally necessary). I've randomly picked 6 of the top 20 shows in the sample to see how they move on this same chart: here's what it looks like.

Law and Order SVU follows the pattern almost exactly; The West Wing comes close, although it has mostly finished its time talk by the end of the first half hour. Other shows depart more significantly; 24 is on track until it doubles back in the last 20 minutes, and Survivor moves left to right but not top to bottom. Dr. Who seems to almost move in the opposite direction of the convention. Still, with just two relatively scarce variables, its surprising to me how well a random sample holds up; it's probably more than a coincidence, as well, that The West Wing and Law and Order are the shows that use the vocabulary the most, as well as using it the most typically. The ones that fail are the most under-represented. For example, Doctor Who hardly talks about times of day at all (perhaps doing it from a time travel topic instead).
[By the way, you might look at these charts and say that they're completely random, this method is bunk, and there's no sign of the left to right trends in the individual shows. I don't think you'd be crazy to do so, based on the charts above--but at least wait until we get to the higher-dimensional stuff before passing definitive judgment.]
Plot arcs
This is interesting, but there are even better ways to approach the general problem of plot arcs. These are charts of motion in two dimensional space: but we have a full 127 dimensions to move around in, one for every topic. Principal Components provides a nice way to plot them all simultaneously. So what I'm doing is taking a restricted set of only 6 documents, one for each sixth in screen time of all the text spoken in all of the movies or TV shows for that period: and calculating the first two components. (Forgive me for linking to one of the earliest series on this blog, a deeper explanation of PCA. And I should note that though I'm plotting 12 chunks, I use 6 chunks of screen time rather than 12 to calculate the components because of the aforementioned problems with shows under 23 minutes.).
Here's we arrive at the heart of this long post. Plotting individual trends, there are lots of ways you can imagine a curve moving. But when we combine all the topics present in all the shows, a single structure emerged. It's quite literally a "plot arc," reduced down from a much more complicated curve moving through 127-dimensional space.

What is this saying? That in the grand corpus of tens of thousands of hours of studio-approved, investor-funded, union-written scripts, two major trends stand out: one set of directional trends, advancing continuously through the course of the film, and one cyclical, through which the language returns back to its origins. It's tempting to get mystical on this, and humanists often to do so when applying techniques like PCA. So perhaps so I should emphasize that it's hard to imagine any other shape coming out of the PCA algorithm with the inputs I put in (which were specifically designed to destroy the genre signals that would ordinarily be output by PCA). Even before I ran it, I was pretty confident this sort of curve would emerge. About the only other reasonable possible option for story structure would be a circle a la Dan Harmon. But a true circle is pretty implausible--we know, intuitively, that the first lines of a story won't be exactly the same as the last, although they may be similar in some ways. So this pure rainbow shape is probably more a confirmation that the method works, more than a radical insight into the nature of narration. (But maybe, some part of me wants to say, I shouldn't give too much up? Maybe it's just a little bit fundamental to narratology? Just don't tell anyway outside this parenthesis I said so).
What's really interesting is not just knowing that there's an arc, but knowing what makes it up. For this, we just have to look at the loadings for the components. Here they are, overlaid: this is not a particularly beautiful visualization and you'd need to expand to really read it, but it gives a better sense of what it means to move through this space. Although there are 127 dimensions, I'm only showing the 15 most important ones on the plot here.

Just for fun, let's put that into a single narrative: the typical script starts among a group of wise-cracking teenagers at the school, making plans for the day to come and the weekend. At the office, however, a dead body is discovered. The wisecracking ceases, and instead the befuddled victims try to describe more accurately how the murder happened, to apologize for their mistakes, and to inspire each other not to give in to defeat but to fight for victory. A heartfelt plea to the Almighty for help lies over their testimony at the trial; and they carefully move into the future, apologizing once again and reflecting on the new truths they have learned.
If anything jumps out at you from this, it might be the dominance of tropes from detective/crime fiction; just as we saw in the last post, those do seem to be some of the strongest elements, and I am somewhat tempted to exclude them from future versions of this. On the other hand, it does capture the centrality of the murder mystery to contemporary television fiction; no other genre comes close in laying out the general scene. Whatever the general principles of plot we learn by watching TV and movies, it's almost certainly deeply inflected by the crime show. (I don't have a place in my personal memory palace for literary criticism, but I believe there's an argument out there that the detective novel is central to the formation of the 20th century novel--anyone?)
But it's important to remember that this is not a general scheme that every show follows--the point is that scripts tend to start with either school scenes, or work scenes, or the discovery of a body. There are many different ways to reach this same plot curve, including some probably nonsensical ones. (Wisecracking at the office doesn't lead to a trial, very often--although we could actually search through the corpus with this method to find the rare episode where this is the case.)
How Individual shows mirror the general plot arc
Just as I was able to overlay individual shows on the toy example of "apology" and "temporality" examples, I can do the same thing with the individual plot arcs. And--lo and behold--those shows tend to follow the same plot arc.

They're not perfect (although ER is pretty close)--but they're also certainly not random. The general curve reflects quite well the overall shape of the arc traced by the aggregate show. (Brief note: because I realized while writing this that to prove efficacy I needed to segregate training data from output, these are arcs that are generated on a subcorpus of the full set specifically designed not to include CSI, ER, or any of the other top 20 shows. So ER is following a plot arc I derived from a batch of shows that don't include any ER, CSI, or any of the other shows you're about to see.)
But eagle-eyed readers might have noticed that the x and y-axes have different numbers than for the archetype. How do these fit in? This is where I got a result that I didn't expect, though perhaps I should have. Here are the twenty shows with the most minutes of dialogue in the movie bookworm, arranged on a single plot. Almost all of them sweep out an arc roughly like the ER or CSI ones (although some are rougher than others, and a few shows, like the "Gilmore Girls" and "The Simpsons," seem to extend the action further in their final scene rather than returning home.)
But although they trace out arcs, they do it in their portion of the plot arc space. (To really make sense out of this chart, you might have to not just click to expand, but open in a separate window, zoom in and zoom out, pan around; or, just truest me). The portions of plot-arc space they land in correspond to genre: the crime shows live in an area something like the early middle of a show, while science fiction camps out after the end of the end.

If you know PCA, this may not initially seem weird to you: after all, the method is usually fairly good at segregating genres. But remember, this is PCA on a space made out of only 6 massive documents, one for each ten minutes of the hour; each TV show is evenly divided across those 6, so the normal avenues for genre signal should be almost entirely muted. But it turns out that the signal for structurality is also tied with the signal with genre. So all those Star Treks are camped out together in the southeast, because the entirety of science fiction language is more "endingy" than even the final scenes of your typical "NCIS" episode. (Particularly on the up-down dimension, which, remember tends to separate the mundane from the eternal. There aren't all that many water-cooler scenes in Start Trek, it turns out; and conversely, the forensics shows aren't dispensing many eternal truths.) What these positions tell us, roughly, is that the genre signal is somewhat, but not immensely, more strong than the plot arc signal even on terms designed to discover plot relationships above all.
So that clustering is interesting enough: but the omnipresence of the curves suggests that they all follow the same path through space in some way, regardless of where they start. Look at each one of these, allowed to expand out: some shows (Charmed, Cold Case, all three Star Treks) follow the curve perfectly, while most others at least move left to right. The two with the biggest problems are Survivor (which obviously faces different narrative issues) and 24 (which I can't really explain away by its plot structure). There's some tendency for shows that start in the southwest quadrant to end less decisively. But even then, they usually follow something like the standard curve.

From a multidimensional point of view, this tells us something really interesting for future research: that plot is about motion through multidimensional space, not about position in it. Most of our existing text analysis toolkits are built around spatial and probabilistic measures that don't really conceive of any possibility for motion; but these archetypal plot arcs are better thought of forces that pull a given script, whatever its starting point, in different directions and with different forces as time unfolds, like tides going in and out.
Breakpoint
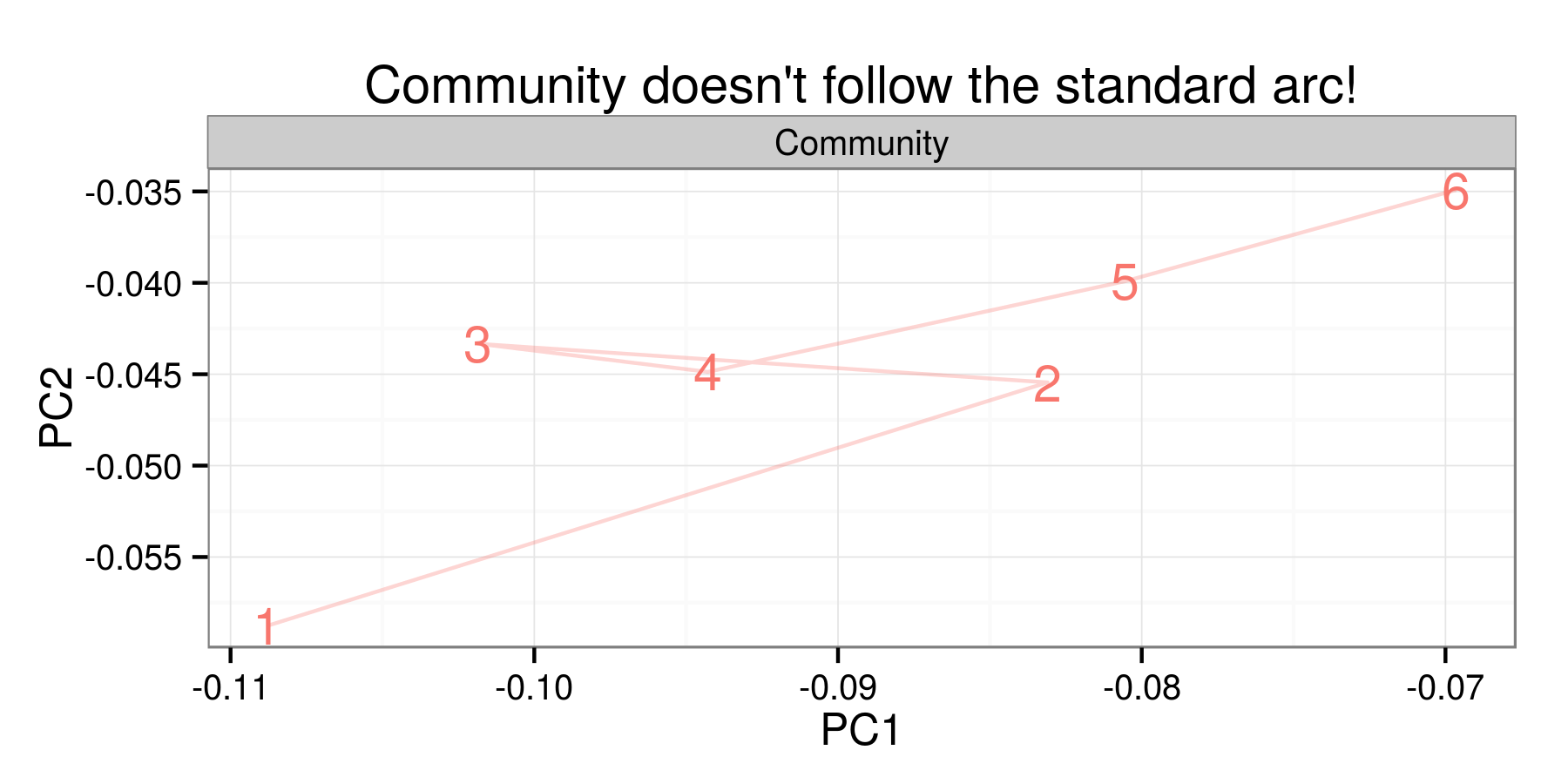
Even at this point, there are some interesting questions that could be answered with the tools at hand. What are the most typical shows? Do any shows have inverted arcs? Do successful shows follow the arc better than failures? Why doesn't Community, Dan Harmon's story circle be damned, follow the standard arc? Some of these are probably best investigated in particular subsections: what can we learn about the transatlantic genre of the cop/detective show, maybe by trying to filter out national vocabulary? I might turn to those low hanging fruit soon, and I'm ending mostly because this post is long enough and the data could use some cleaning. (Next time I write on this, I'll be using a slightly different topic model, and possibly a 1-minute chunking rather than a three-minute one). But I could easily fill out another half-dozen questions in that same vein right now, and I'm sure you can to.
{kind=link}
One extremely important observation I've noticed, but haven't had time to fully plumb, is this: TV shows show much greater regularities of form than do films. This could be data problems, but I suspect it's real; everything about the TV system enforces heavy constraints and tight structures that even a 90-minute movie can more easily flout. (Particularly because my topics seem to be better capture themes of interpersonal conflict than individual growth).
But because this is getting out past where I usually take text analysis, really pushing the investigation farther may require some really difficult thought. How best to capture motion along arcs as a phenomenon in itself? I could just multiply my multidimensional space across 6 more dimensions, but I'm already pushing the limits of the data. The closest standard technique might be transition matrices but applied to topic spaces rather than words.
In some ways, the problem resembles musicology, a field which has a firm grasp on structure, more than text. The math reminds me in particular of Dmitri Tymoczko's "A geometry of music," which treats chord progressions as paths through multidimensional space. But the time spans that we're working with are much greater, the kind of spaces where you want a sort of Schenkerian analysis of plot. The pure formulaic banality of much network TV makes this project particularly appealing here; if the sitcom episode is a rondo and the hourlong drama a sonata form, each cinematic drama probably more closely resembles a meandering, idiosyncratic tone poem. (To say nothing of the novel. Though I'm sure there are ways this could be creatively deployed on that white whale of narrative, I doubt the signal for plot arcs would be anywhere near as strong).
But there's also a danger that analogy to high-level musical structures implies. Schenker's Ursatz can seem like a weird cross between a mirage and a tautology. As I said, some kind structures like these have to exist just because of the math; that doesn't they're real in any meaningful sense, or that they're useful. So I'm curious what anyone else thinks on this one in particular.
Appendix
Two images with a lot more shows are graphically problematic, but might help you to locate your favorite show or find some errors. The prettiest way to handle this would be an interactive graphic with D3 using my d3.layout.trail library, so you could see the curves unveil in space when you added a show; but I've got get a little actual history done this week, too, so maybe not.
Appendix 1 (open in new window): Top 200 shows, in one giant plot. Shows the tendency for southwestern shows to end closer to the middle of the plot arc, which worries me a bit: and the tendency of all shows to cluster in the portions that form a sort of macro version of the arc, which, I don't even know.

Appendix 2 (open in new window and expand): Top 200 shows in alphabetical order, faceted one per frame.

Wow, this is great stuff. You have analytically uncovered the "three acts" theory of story structure. As Julius Epstein, who wrote Casablanca, said to Vincent Sassone who was taking a writing course: "You're wasting your money. I'll tell you how to write a screenplay in three sentences. Act I, get your guy up a tree. Act II, throw rocks at him. Act III, get your guy outta the tree." Basically, there's the setup, the complications and the resolution.
ReplyDeleteIn other words, the structure you are detecting is completely intentional. It's also pretty old. You should dump some Euripides or Aeschylus into your analyzer. It's probably cross cultural too.
Thanks. You're right that it's close to a traditional three-act structure, so it's probably worth asking what some of the differences from that might be. One is proportions-- compared to golden age or modern Hollywood, the "middle" here is longer than it should be. (Does that make it more like longer five-act plays?) Another might be content, actually. If I were going to describe the three batches of words, I might call them something like 1. Calm 2. Action 3. Reflection. The amount of post-facto exposition built into some dramatic forms is really different.
DeleteAnd then there's the whole detective show thing... You can make the Epstein quote apply to that, but it's obviously by analogy. (Actually, I think the quote applies better to sonata form in some ways than it does to either detective stories or to romantic comedies. What's interesting about this space is that it applies to all the different genres fairly well--though it's totally unclear to me right now whether that's based on any real similarities, or on just having enough data to wrap them all in, as in my phony plot example.
Unbelievably good! Got this recommended by the Browser and it didn't disappoint. Great work.
ReplyDeleteNever seen so much blood come out of a stone before.
ReplyDeleteThis is really excellent stuff. Basic structural principles of narrative. I kind of can't even summarize my response. Superimposing the arcs of different shows is an excellent viz idea.
ReplyDeleteObviously, going to want to do this with novels as well. One could group novels by author or genre to create patterns as strong as the ones you're getting from television serials.
Whew! Awesome idea.
Wheel, reinvented. Congratulations.
ReplyDeleteThe paragraph about Star Trek is especially wild. Deep relationship between plot structure and genre?!?!? Structuralists should looooove this stuff.
ReplyDeleteWhat follows is pasted in from an e-mail from a friend that I want to respond to here:
ReplyDelete> [...] And believe it or not I actually buy his [Dan Harmon's]/your/Joseph Campbell's mythology stuff: when I read Campbell a long time ago I couldn't see the point of his superficial all-myths-say-the-same-thing structuralism, but as a barometer of today's highly formalized pop culture mythology it actually makes sense.
> Have I given you my long-winded paean before about how The State guys (David Wain, Michael Showalter, Michael Ian Black, etc.) are actually pretty great narratologists? Their shows are constantly commenting on how the consistency of modern narratives have warped our sense of what counts as significant and eventful. But those deconstructions are usually equivalent to close readings rather than radical structural changes, and I'll be if you ran Wet Hot American Summer, Reno 911, or Stella through the bookworm bot the plot arcs wouldn't surprise you.
> But that doesn't mean I'd agree with your more dismal suspicion that Schenkerian sketches of this kind are banal or tautological. Cognitive narratologists are really trying to figure out what kind of conventional narrative order the mind (in both the individual sense and the cultural one) needs or wants or uses — not as a salve but as a scaffolding that can support a lot of renovation/rethinking at different levels.
> Or to put it another way, we are rarely aware of how concepts of time or causation are narrative fabrications until they're pointed out to us. The conceptual blending guys, Fauconnier and Turner, have talked about how our concept of "punishment" relies on exactly the kind of narrative that you pinged in one of your earlier charts (feel/hate/sorry/hurt/wrong fault): this is maybe an obvious one because we are more aware of judgments about guilt and retribution being selective readings of a situation because they're rooted in legal systems which are overtly deliberative. But you're also drawing out a lot of nonobvious conventions that are important for highlighting how deep our mythologies run (came/knew/wanted/saw/day/remember took is one of my favorite topics, and the Survivor pseudo-coda at point 4 in your PCA chart is very interesting too). I have a pet theory about the meta-arcing of your mini arcs but I'll save that for another day.
On the first paragraph, I think this actually a pretty important point--I see a few people here complaining that we all know that stories follow three-act structures, but actually the modern television three-act structure is a highly historical artifact that seems to be reinforced through strong conscious work in specific media right now. (It's hard to plot specific films, but even the most banal Hollywood films won't be so formulaic as TV, I believe. Or at least, that's one of the routes that can be explored with methods like this, but are difficult to do otherwise.)
DeleteYep. It's also going to be an interesting question how far these components of "plot" for television do or don't overlap with the analogous components for prose fiction.
DeleteIntuitively I tend to agree with Ben that this particular plot space is going to turn out to be pretty specific to television. E.g. the "sorry" topic feels televisual; we might borrow a phrase from Seinfeld and call it the "hugs and learning" topic. (Speaking of which, I wonder about Seinfeld...)
But. We could be wrong.
Kurt Vonnegut did something like this for his thesis at U of Chicago. The faculty laughed him out of the University. Good luck for everyone who enjoyed his later work in fiction.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteHey Ben -
ReplyDeleteThis is really, really neat. I enjoyed this whole post and think there is a lot to what you've uncovered.
But I do worry that the fact that whole genre-s are more 'ending-y' is not so much a discovery as an issue with the method, an indication that genre features need to be controlled for more systematically.
Seems to me that progressing faster-or-slower through the plot is something that can vary by genre, but that any method which effectively says s/t like: well this genre starts at the end and keeps going is no longer doing something that passes the "reasonable" sniff test for plot structure.
I realize that what you are saying in the text of the blog post is more nuanced than this, but on first pass I think the data may simply indicate that star-trek is full of words that are ending-y for other genres, and so the classifier doesn't do a very good job on star trek. And indeed on many other specific shows.
Notwithstanding that it does seem to get meaningful results out of the aggregate of all shows.
Very cool!
About "the reasonable sniff test for plot structure" ... I just want to suggest that finding a digital proxy for "what critics mean by plot" might be a bad Grail to set off in quest of.
DeleteFirst, because it would require very ambitious NLP. For instance, there is actually no rule that a novel has to have a single plot. Critics often talk about multiple interlacing plots. There could also be different narrators ... and pretty soon we are talking about a problem that is so to speak AI-complete.
The other reason I think it's a bad Grail is that critics may not actually have a very well-formed conception of plot in the first place. I mean, we're still arguing about it.
So I think the path to take here is probably to acknowledge that you're seeing linguistic and topical contrasts between the beginnings, middles, and ends of works -- things that are related to, but not the same thing as, our received (murky) understanding of the concept “plot.”
The problem Erez is noting would still be meaningful then, but it becomes merely a question of choosing a reference point. When we say "beginnings and ends are less far apart in scifi," we could mean that a classifier trained on SF finds it harder to distinguish them than a classifier trained on detective fiction finds it to distinguish beginnings and ends in detective fic. Or we could mean that they are less far apart by a metric trained on the whole collection. Both questions might be meaningful (though I agree w/ Erez that the first formulation is probably what we're more likely to be asking). Neither question is quite what we thought we meant by "plot," but imho, that's okay.
Hi Erez! Yes, I worry about the classifier a bit. Still, I think there's a chance even the strongest version of the Star Trek thing might hold. If typical episodes of TV shows tend to deal with big philosophical questions just as the beginning and end, and Star Trek does the same but deals with much bigger questions and deals with them all the time, then this might be a fair characterization. But I agree that it's unlikely that a first-pass method like this is actually clocking into exactly those features--what disturbs me the most is that the second-to-last chart shows some very strange patterns, where the arcs would look better if distorted to be rotated around a focal point. Something's fishy, and I'm going to pull away from PCA after about one more post.
ReplyDeleteBut I don't think I'm saying that "Star Trek" starts at the end, exactly: I'm saying it starts at the end compared to other plots. Say we were looking instead a metric for identifying laugh lines, and I found that action movies started off really jokey and gradually got less humorous. Then that method was applied to comedies, and found that they ended at a well more beginning-y place than the action movies began, and started at a far laughier place. That wouldn't show a problem with the classifier, because laughter-ratios actually are connected to genre; it would just be a generally interesting finding that both genres got less funny as they progressed. What's important are not the points in multidimensional space, but the directionality of movement among them. So PCA as a "classifier" doesn't do a great job on Star Trek--but the higher-dimensional classifier that tags it as "plotty" does work fairly well, because it moves through vector space from its beginning in a relatively predictable way.
But of course you and Ted are right that it may be disingenuous to call this "plot." "Structural arrangement of thematic elements" would be something more like what's actually going.
Fantastic:
ReplyDelete"the problem resembles musicology... So I'm curious what anyone else thinks on this one in particular."
I'm intrigued by the comparison to Schenkerian analysis; actually excited just to see another "word person" who knows what Schenkerian analysis is (though the more general, successor notion of "voice leading analysis" might be sufficient).
One thing to say is that Schenker proposed a kind of symmetry between analysis and generation: the structures revealed by reduction were the structures that composers working in the framework of tonal harmony elaborate (through techniques like arpeggiation or stepwise motion) in the first place. The basic structures (the tonic triad, the descending line (3, 2, 1)) are not merely what are revealed by analysis, but also what, through elaboration, generate the music as we hear it. And Schenker had reason to believe in this kind of symmetry because he studied the same kinds of composition techniques (harmony and counterpoint) that composers like Bach and Beethoven had studied centuries earlier.
Voice leading analysis is not only, in its conception, symmetrical but homogeneous. The structures that it identifies are (except in some weird cases where it must posit them, but that aside) actual notes that occur in the music. So reductionist analysis takes place in the same medium as the object it reduces. You can *play* the product of an analysis on a piano.
As I think you acknowledge, we should be hesitant to treat your PCA analyses in the same way. Topic modeling (at least as Blei describes it) relies on the fiction that "topics" generate documents, but it's important that we neither forget that this is a methodological fiction nor let it slip into an assertion. Put differently: the tonic and the descending line may (at least plausibly) generate the surface structure of music through elaboration. But TV writers are not generating scripts out of probabilistic collocations of words (certainly not as they occur in set 3 or 6 min segments). Insofar as we conceive of TV writing as having generative principles (it probably has many of them) at all, there's no reason to think those principles are composed of words, much less collocations of words - they may be "plot-points" or "tropes" or "situations" or "story elements. So your analysis is heterogeneous where Schenker's is homogeneous: topics may usefully correlate with some generative structure or another (the debate about whether this is "plot" or not is a useful one), but they are not those structures. This reminds me of Moretti's observation of the distinction between objects of history and objects of knowledge. The topics you identify are objects of knowledge but stand at a distance from the objects of history.
I think your post is pretty clear and right on about all of this - just wanted to help elaborate the comparison.
One more note about voice leading analysis: the point of its reductions (stripping away elaborations, simplifying rhythm, compressing prolongations, etc.) is not to "discover" the same hidden structure in every score (in the way that archetype analysis gets its thrill from discovering "the hero" in different texts). Rather, identifying the Ursatz (or rather positing it - you're right to see it as a kind of tautology) makes it possible to analyze the variously employed techniques of elaboration that individuate different works. The analogy to your post: the arc structure you "discover" is less interesting than the subsequent analyses of deviations from arc structure that it permits. (Though again, I suppose these to be deviations from a statistical norm, not different elaborations of underlying structures, as in Schenker, though perhaps you could come up with a taxonomy or classification of deviations as he did with elaborations.)
Thanks for such a thought-provoking comment. You've given me enough to say that I've discovered for the first time Blogger's limit on comment lengths. My musicology is all rusty and undergraduate, so I'll probably be wrong some spots about what I'm about to say. (On the other hand, this whole post was about narratology, which I'm really far less entitled to spout about). But let me give it a shot.
DeleteIn many ways I would feel much more comfortable about my own analysis if it were about words, not topics, because I could at least make an argument (one I know you'd disagree with, probably correctly) that plots are in some sense built out of words. But alas, it would be much more illegible, and that's the point. Even if it were legible, though, you are clearly correct that the space of tokens described by the algorithms here is much farther than the one experientially from authors than the one of notes is from that navigated by composers. On the shorter horizons of voice-leading, in music they are nearly one and the same; that's one of the things so interesting about Tymoczko's work. (And probably others--I only really know him because he taught at Princeton when I was a grad student).
Things are further complicated by the fact that even where "tropes" or "plot points" do exist, they are far less pervasive than the universality of tonality as it existed in the common practice period, and far less rigorous. I think you're right to point to Schenker's taxonomy of deviations as the thing I'm really interested in here, or why I see him as more "long-form." And those deviations are themselves important forms: evidently (Lord, I had forgotten how audacious this stuff gets) sonata form are the type where you hang out on two and then go back to three before heading back on down. So there's some hope of salvage.
To pursue the analogy with the best face of Schenkerian analysis or voice leading, I'd probably have to choose between two different statements:
1. Each major genre ("romantic comedy," "cop show," etc.) is essentially its own "tonality," and episodes can draw from multiple Ursatzen or depart from the pattern altogether.
2. There really are shared elements that tend to be elaborated upon--a uniform narrative structure, or at least set of gravitational poles, that most narratives tend towards. (I suspect these will be more thematic--"reflecting on progress"--than topical--"a marriage").
(continued)
(part ii)
DeleteBoth of those suggest that maybe this is wrong musicology to talk about. Rather than the analogy being the common practice period, it should something more like the classical style. (Less exciting than grand theories of narrative, but also more useful in understanding individual works). My undergrad music theory seemed to be dominated by Caplin, which offers a taxonomy of medium-sized forms (sentences, periods, etc) that are slightly less rigorously rooted in the core elements of voice-leading. (Though Schoenberg's Harmonielehre, Caplin's back-progenitor, has as I recall an enormous emphasis on voice-leading; am I creating a false distinction?).
And in the classical style, the constitutive elements of structure aren't exactly the notes or the harmonies that are the same as the notes; they're something else more impressionistic, closer to plot points. I'm thinking now, for instance, of Charles Rosen's analysis of why the Waldstein Sonata goes to the mediant rather than the dominant for the second theme in the exposition. As I remember, it could be caricatured as "because four sharps is four times as dominant-y as one."
Which isn't to say that musical structure isn't much more real than plot arceology. (Why have I not coined that phrase until now?) But particularly in the most highly constrained forms--sitcoms, commercials, Reuters articles, possibly hymns--I think that might suggest there are forms where musicology could offer a model of a less internalist language than voice leading.
Finally, you are absolutely right that the really interesting questions are about the individual deviations from the overall arcs. (By which I mean the multidimensional paths through token/topic space, not necessarily the 2d representations I'm talking about here). I'm still stuck, though, on the prior question--if there anything there stable enough to really draw a comparison to? Some of what I wrote above, and has come out on Twitter, makes me not want to completely close the door on that possibility. But certainly, the spaces I'm outlining so far aren't going to be enough to help a reading of "Memento" (or whatever) in any humanistic way yet. The question is, I guess, whether there is any way to taxonomize formal practices analogous to the sonata or the rondo on this that are common enough to permit general comparison.
Whew! Thanks for taking the time to formulate such an awesome reply! I hope it's okay if I also respond in parts, and piecemeal at that. Like you, I'm doing my best to recall details from the theory and composition courses I took as an undergrad music major - so 15 years back now. From the look of it, you recall more of the intricacies than I do, but your mention of Caplin brought back lots of memories. The kind of formal analysis Caplin exemplifies is more responsible for my current interest in syntax than anything else in my studies, which also reinforces my general dissatisfaction with purely lexical analyses of language: in the interest of counting words, methods like topic modeling discard syntax. The procedure isn't illegitimate - we're always sacrificing one level of detail in order to see patterns at a different level - it just happens to sacrifice the aspect of language I care about most (and the one that most exercises actual linguists, for that matter). So I do think your approach is more Schenker than Caplin, since it disregards the syntax at the level of the sentence ( i.e. the local harmonic progressions) in order to detect larger lexical patterns (the Ursatz, the arc in flattened topic space). The analogy is never direct or satisfactory, but to my mind modeling topics is a bit like measuring the frequency of collocation of I V64-53, vi, IV, etc. within some segment of a sonata. It may tell you what tonal space you're in, but it necessarily ignores whether in their sequence the chords compose a perfect cadence, a false cadence, a half cadence, etc. But maybe this analogy just reveals, which is to say repeats, my particular stake in syntax against the isolation of lexis, which you are more than free to disregard.
DeleteI do think that comparisons to other, established modes of analysis (whether in the same medium, as with narratology, or a different medium like music) are crucial for more than our own nostalgic reasons: they help to understand the stakes and procedures of any new mode of analysis like the "arceology" (nice!) that you've detailed in your post. Comparisons tell us what we're up to.
One place to push further on the comparison is dimensionality. I don't know anything about Dmitri Tymoczko's approach beyond what I could glean from his website, but music has been understood mathematically and geometrically since Pythagoras at least. Setting aside the string or column of air that needs to vibrate in space, music divides the single axis of time at two different scales: on a very rapid scale (hundreds or thousands of oscillations per second), i.e. the frequency of pitches, and at much slower scale (tempo as measured in beats per minute), i.e. rhythm. We experience these ways of dividing time on different scales as two independent axes, and conventional western music notation depicts them that way: pitch on the vertical axis, rhythmic time on the horizontal axis. (I'm leaving out other potential axes of differentiation like instrumentation.) In tonal music both pitch and rhythm are largely governed by ratios of whole numbers (I know this isn't completely true, as the history of tuning shows, but it's basic nonetheless.) A whole measure gets split into quarters, eighths, sixteenths, triplets, etc. A fundamental frequency gets fractioned into partials by whole number ratios. So with tonal analysis you know both what the axes of possible reduction are and, more or less, the underlying system of ratios that differentiates rhythms and pitches along their respective axes. I wouldn't say that these axes are more "real" than principal components (both are real) but they are intuitive and necessary: to get transcendental about it, they are Kantian forms of intuition, the condition of experiencing any music whatsoever. At any rate, it is along the axes of pitch and rhythmic time that music is experienced, and along those same axes that different kinds of analyses and reductions occur.
Now with your arcs we're in a much more difficult situation. The axes don't designate anything so simple or transcendental as pitch and rhythm; rather they are (if I'm getting the details right) reductions of 127 dimensions, each defined by a bundle of words that appear together with some frequency, to two dimensions. Let's put aside the vexed relation btw lexis and semantics and just say that you're dealing with semantic space. How many dimensions does semantic space have? How are those dimensions organized? How is space divided, marked, given distinct zones within those dimensions? I have no idea. In the absence of given, intelligible axes like pitch and rhythm, I suppose you could reorient the axes so that they align with some identifiable semantic feature, but then you'd risk losing the arc pattern to gain intelligibility, and part of the thrill of the whole thing is the extent to the reduced axes are "acheiropoieton," made by no hand. Alternatively, you could accept that PC1 and PC2 are strictly unintelligible, but that's rather unappealing, since it means both, yes, there's a real structure, and no, we don't have existing concepts to explain it. Those are the antinomies - is there a middle way? There may be, and perhaps you've already named it: one "directional" trend, and one "cyclical." Your arcs show that directionality and cyclicality manifest along multiple, complex axes of semantic space. This may be the furthest that one can plausibly push intelligibility. I also think it's important to hold out the possibility that culture creates complex, identifiable patterns that culture does not have the resources to comprehend. You may be bumping up against that limit.
DeleteIn my first post I said that voice leading is homogeneous whereas your procedure is heterogeneous. You proposed instead a metaphor of proximity: your arcs are "further" from the texts they represent than Schenker's analyses were to the compositions they analyzed. I think that's right: my initial binary was too stark. And I'm more willing than you expect to accept the idea that "plots are in some sense built out of words." (For a long while it was the fashion for literary scholars to suppose that there's nothing outside of the prison house of language.) Plots probably are built out of words: just not the words that appear in your topics or even in the texts themselves. Or at least, we can't assume that the words that build plots will appear in texts in the way that the dominant invariably appears in a Hayden composition (on an accented beat, not just a passing note, no less, and almost always at the beginning and/or end of a "sentence").
DeleteThis is actually a pretty intuitive point. Journalists structure their opening and ending sentences using the concepts of lede and kicker. But those words almost never appear in the sentences they write. Likewise, Greek tragedians had some idea that they should have a scene of recognition towards the end of their plays. Even before Aristotle named these scenes, they might have conceived of them using the word "anagnorisis" (recognition). But with possible exceptions the word anagnorisis doesn't appear in those scenes of recognition. All but the most artless or self-consciously artful (Joss Wheedon?) TV writers establish standard character types like the "ridiculously average guy" (http://tvtropes.org/pmwiki/pmwiki.php/Main/RidiculouslyAverageGuy) or the "plucky girl" (http://tvtropes.org/pmwiki/pmwiki.php/Main/PluckyGirl) without using the words average or plucky. So yes, plots are made out of words, but only rarely the ones that appear in the text and therefore in topics or in PCA reductions of topics.
Sorry for taking time to explain obvious stuff. What's more interesting to me are times where an absent word structures a text as what Stephen Booth calls "an undelivered pun." My favorite example is the Herbert poem "Love III," which I taught just last week:
Love bade me welcome: yet my soul drew back,
Guilty of dust and sin.
But quick-eyed Love, observing me grow slack
From my first entrance in,
Drew nearer to me, sweetly questioning
If I lacked anything.
“A guest," I answered, “worthy to be here”:
Love said, “You shall be he.”
“I, the unkind, ungrateful? Ah, my dear,
I cannot look on thee.”
Love took my hand, and smiling did reply,
“Who made the eyes but I?”
“Truth, Lord; but I have marred them; let my shame
Go where it doth deserve.”
“And know you not," says Love, “who bore the blame?”
“My dear, then I will serve.”
“You must sit down," says Love, “and taste my meat.”
So I did sit and eat.
The absent structuring word is "host": both someone who welcomes a guest and the sacramental bread that is also the body of Christ. Love starts as the first kind of host and becomes the second. The whole poem is a pun on a word that doesn't appear in it. (A.J. Greimas and other structuralists love this sort of thing and identify fantastic instances of it in French poetry.) If topic modeling might generate signs that, as effects, point back to absent words like anagnorisis or climax, or lede or kicker, it hard to imagine it pointing us back in a legible way to a word like "host."
Anyway, I'm sharing the notion of an absent structuring word as a roundabout way of making the following point about the proximity of an analysis. The elements of a Schenkerian analysis (the tonic, dominant, etc.) nearly always appear as a real (metrically prominent) element of the work itself. Only in rare cases do the words that structure a plot (or a poem, or a news story) appear in the text they structure.
I wanted to end with a question. Like many others, I think we're living in a golden age of television, something like a post-Wire era. One thing that makes the Wire and other shows like it so satisfying is that they have a story arc that stretches over a whole season, or even multiple seasons, rather than a single episode. In a real sense they are not episodic; the hour long episode is merely the delivery unit; the season is the unit of composition and experience, narrative development and closure. Each episode is more like a chapter in a Victorian novel than a short story featuring a known cast of characters. The Wire isn't on your big chart, but other arguably developmental shows like Mad Men or Weeds are. Even still, it's hard looking at episode averages to get a sense of whether longer, multi-episode story arcs register in your graph. Do they? If you plot all the episodes of developmental shows like Breaking Bad, would it form a larger arc structure, vs. episodic shows like CSI or MacGyver, which presumably retread the same space? Could your arcs, in other words, give us a way to measure how episodic or developmental a show is?
DeleteThanks again for your post, and for the ensuing conversation!
Hi, your post is fascinating, thanks for sharing it!
ReplyDeleteI am a master student and a newbie on topic modeling, but I have one question. Is the topic model trained to recognize a specific set of topics or is it trained only on script chunks (regardless their content)? I find LDA interesting but I would like to understand how to use it properly in this kind of analysis.
Thanks again!