Here's an animation of the PCA numbers I've been exploring this last week.
There's quite a bit of data built in here, and just what it means is up for grabs. But it shows some interesting possibilities. As a reminder: at the end of my first post on categorizing genres, I arranged all the genres in the Library of Congress Classification in two dimensional space using the first two principal components. PCA basically find the combinations of variables that most define the differences within a group. (Read more by me here or generally here.). The first dimension roughly corresponded to science vs. non-science: the second separated social science from the humanities. It did, I think, a pretty good job at showing which fields were close to each other. But since I do history, I wanted to know: do those relations change? Here's that same data, but arranged to show how those positions shift over time. I made this along the same lines as the great Rosling/Gapminder bubble charts, created with this via this. To get it started, I'm highlighting psychology.
[If this doesn't load, you can click through to the file here]. What in the world does this mean?
Tuesday, February 22, 2011
Sunday, February 20, 2011
Vector Space, overlapping genres, and the world beyond keyword search
I wanted to see how well the vector space model of documents I've been using for PCA works at classifying individual books. [Note at the outset: this post swings back from the technical stuff about halfway through, if you're sick of the charts.] While at the genre level the separation looks pretty nice, some of my earlier experiments with PCA, as well as some of what I read in the Stanford Literature Lab's Pamphlet One, made me suspect individual books would be sloppier. There are a couple different ways to ask this question. One is to just drop the books as individual points on top of the separated genres, so we can see how they fit into the established space. By the first two principal components, for example, we can make all the books in LCC subclasses "BF" (psychology) blue, and use red for "QE" (Geology), overlaying them on a chart of the first two principal components like I've been using for the last two posts:
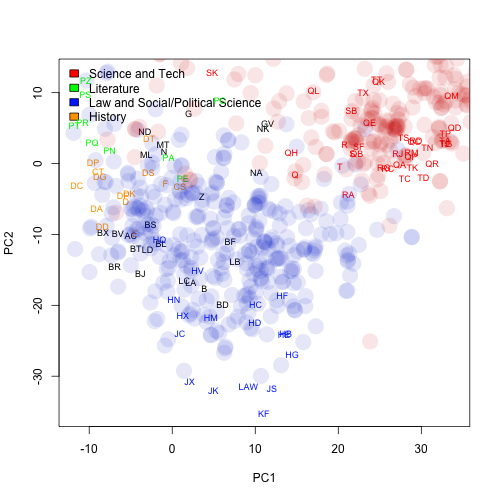
That's a little worse than I was hoping. Generally the books stay close to their term, but there is a lot of variation, and even a little bit of overlap. Can we do better? And what would that mean?
{kind=link}
That's a little worse than I was hoping. Generally the books stay close to their term, but there is a lot of variation, and even a little bit of overlap. Can we do better? And what would that mean?
{kind=link}
Thursday, February 17, 2011
PCA on years
I used principal components analysis at the end of my last post to create a two-dimensional plot of genre based on similarities in word usage. As a reminder, here's an improved (using all my data on the 10,000 most common words) version of that plot:

I have a professional interest in shifts in genres. But this isn't temporal--it's just a static depiction of genres that presumably waxed and waned over time. What can we do to make it historical?
I have a professional interest in shifts in genres. But this isn't temporal--it's just a static depiction of genres that presumably waxed and waned over time. What can we do to make it historical?
Monday, February 14, 2011
Fresh set of eyes
One of the most important services a computer can provide for us is a different way of reading. It's fast, bad at grammar, good at counting, and generally provides a different perspective on texts we already know in one way.
And though a text can be a book, it can also be something much larger. Take library call numbers. Library of Congressheadings classifications are probably the best hierarchical classification of books we'll ever get. Certainly they're the best human-done hierarchical classification. It's literally taken decades for librarians to amass the card catalogs we have now, with their classifications of every book in every university library down to several degrees of specificity. But they're also a little foreign, at times, and it's not clear how well they'll correspond to machine-centric ways of categorizing books. I've been playing around with some of the data on LCC headings classes and subclasses with some vague ideas of what it might be useful for and how we can use categorized genre to learn about patterns in intellectual history. This post is the first part of that.
***
Everybody loves dendrograms, even if they don't like statistics. Here's a famous one, from the French Encylopedia.

And though a text can be a book, it can also be something much larger. Take library call numbers. Library of Congress
***
Everybody loves dendrograms, even if they don't like statistics. Here's a famous one, from the French Encylopedia.

That famous tree of knowledge raises two questions for me:
Friday, February 11, 2011
Going it alone
I've spent a lot of the last week trying to convince Princeton undergrads it's OK to occasionally disagree with each other, even if they're not sure they're right. So let me make one of my notes on one of the places I've felt a little bit of skepticism as I try to figure what's going on with the digital humanities.
Since I'm late to the party, I've been trying to catch up a bit on where the field is now. One thing that jumped out is how wide-ranging the hopes are for what the digital humanities might do if they take over the existing disciplines or create their own. Being a bit of a job market determinist myself, I wonder if the wreckage many see in the current structure of the humanities doesn't promote a little bit of millenarian strand about how great the reconstruction might be. I feel occasionally I've stumbled into Moscow 1919 or Paris 1968; there are manifestos, there are spontaneous leaderless youth, and in the wreckage of the old system, anything seems possible for the new technological man. Digital humanities, to exaggerate the claims, will create the mass audience academic historians have lost, will reaffirm the importance of public history in the field, will create new fields with new jobs, will break down the boundaries between disciplines, will allow collaborative history to finally emerge. And it might be in danger if it's co-opted by the powers-that-be, as John Unsworth finds many worrying (pdf).
Paris 1968 is an exciting place to be. I've been watching Al-Jazeera all week. But all these transformations promised by DH won't happen all at once, and some of them won't happen at all. As I try to write some of this up for a Princeton audience (which is why, along with the start of our term last week, I'm not blogging much right now) I'm thinking about what it takes to get skeptical historians on board, and what parts of the promised land might put them off.
The thing I'm mulling over: collaboration. A colleague said to me yesterday he thought the digital humanities will come and go before most historians ever stopped working alone, and I think I tend to agree. I'm pretty much agnostic on the need for collaborative history, myself. Certainly, digital humanities open up fascinating new prospects for collaborative projects. But so far as we're trying to get anyone established on board, an insistence on collaboration might be as much a liability as a benefit. I'm signing up for a THATcamp, but I have to admit a bit of trepidation about putting in volunteer work onto anything that isn't mine. Not just for selfishness, but because we often have funny standards about academic work it's difficult to impose on others. I went to a talk this week where one participant says he refuses to use the words "idea" or "concept." No one can live up to all the constraints we might want to put on work, but it's often fascinating to see what people come up with when we let them do things wholly their own way. Labs aren't always amenable to humanist practices because it's critically important for the health of our disciplines that we don't agree on methodology.
Luckily, then, I've been most struck by in the last couple months is how far one can go it alone right now--unlike the early years of humanities computing (or so I gather), you don't need teams to get computing time, all the truly technical work of digitization, OCR, and cataloging has been done by groups like the Internet Archive, and free software makes it possible to get started on some forms of analysis quite quickly. It's quite possible for someone at a university without any digital humanities infrastructure to do work in text mining or GIS without having a full lab or collaborative team behind them. Sure, it's harder than firing up an iPad app; but I'm not sure it's that much worse than all the commands plenty of senior academics learned in the dark ages to check their e-mail on pine or elm.
What about all the collaborative the labs and programs we already have? Clearly they do more than anything to advance the field, and it's hard to imagine all the great work coming out of GMU or Stanford (say) happening with lone scholars. But it's equally hard for me to imagine that the digital humanities will have actually succeeded until there's a lot of good work coming out that doesn't need the collaborative model, and that answers to some of the expectations of solitary scholars about how humanistic work is produced. At least, that's what I'm thinking for now.
Since I'm late to the party, I've been trying to catch up a bit on where the field is now. One thing that jumped out is how wide-ranging the hopes are for what the digital humanities might do if they take over the existing disciplines or create their own. Being a bit of a job market determinist myself, I wonder if the wreckage many see in the current structure of the humanities doesn't promote a little bit of millenarian strand about how great the reconstruction might be. I feel occasionally I've stumbled into Moscow 1919 or Paris 1968; there are manifestos, there are spontaneous leaderless youth, and in the wreckage of the old system, anything seems possible for the new technological man. Digital humanities, to exaggerate the claims, will create the mass audience academic historians have lost, will reaffirm the importance of public history in the field, will create new fields with new jobs, will break down the boundaries between disciplines, will allow collaborative history to finally emerge. And it might be in danger if it's co-opted by the powers-that-be, as John Unsworth finds many worrying (pdf).
Paris 1968 is an exciting place to be. I've been watching Al-Jazeera all week. But all these transformations promised by DH won't happen all at once, and some of them won't happen at all. As I try to write some of this up for a Princeton audience (which is why, along with the start of our term last week, I'm not blogging much right now) I'm thinking about what it takes to get skeptical historians on board, and what parts of the promised land might put them off.
The thing I'm mulling over: collaboration. A colleague said to me yesterday he thought the digital humanities will come and go before most historians ever stopped working alone, and I think I tend to agree. I'm pretty much agnostic on the need for collaborative history, myself. Certainly, digital humanities open up fascinating new prospects for collaborative projects. But so far as we're trying to get anyone established on board, an insistence on collaboration might be as much a liability as a benefit. I'm signing up for a THATcamp, but I have to admit a bit of trepidation about putting in volunteer work onto anything that isn't mine. Not just for selfishness, but because we often have funny standards about academic work it's difficult to impose on others. I went to a talk this week where one participant says he refuses to use the words "idea" or "concept." No one can live up to all the constraints we might want to put on work, but it's often fascinating to see what people come up with when we let them do things wholly their own way. Labs aren't always amenable to humanist practices because it's critically important for the health of our disciplines that we don't agree on methodology.
Luckily, then, I've been most struck by in the last couple months is how far one can go it alone right now--unlike the early years of humanities computing (or so I gather), you don't need teams to get computing time, all the truly technical work of digitization, OCR, and cataloging has been done by groups like the Internet Archive, and free software makes it possible to get started on some forms of analysis quite quickly. It's quite possible for someone at a university without any digital humanities infrastructure to do work in text mining or GIS without having a full lab or collaborative team behind them. Sure, it's harder than firing up an iPad app; but I'm not sure it's that much worse than all the commands plenty of senior academics learned in the dark ages to check their e-mail on pine or elm.
What about all the collaborative the labs and programs we already have? Clearly they do more than anything to advance the field, and it's hard to imagine all the great work coming out of GMU or Stanford (say) happening with lone scholars. But it's equally hard for me to imagine that the digital humanities will have actually succeeded until there's a lot of good work coming out that doesn't need the collaborative model, and that answers to some of the expectations of solitary scholars about how humanistic work is produced. At least, that's what I'm thinking for now.
Wednesday, February 2, 2011
Graphing word trends inside genres
{kind=link}
Genre information is important and interesting. Using the smaller of my two book databases, I can get some pretty good genre information about some fields I'm interested in for my dissertation by using the Library of Congress classifications for the books. I'm going to start with the difference between psychology and philosophy. I've already got some more interesting stuff than these basic charts, but I think a constrained comparison like this should be somewhat more clear.
Most people know that psychology emerged out of philosophy, becoming a more scientific or experimental study of the mind sometime in the second half of the 19C. The process of discipline formation is interesting, well studied, and clearly connected to the vocabulary used. Given that, there should be something for lexical statistics in it. Also, there's something neatly meta about using the split of a 'scientific' discipline off of a humanities one, since some rhetoric in or around the digital humanities promises a bit more rigor in our analysis by using numbers. So what are the actual differences we can find?
Let me start by just introducing these charts with a simple one. How much do the two fields talk about "truth?"

Tuesday, February 1, 2011
Technical notes
I'm changing several things about my data, so I'm going to describe my system again in case anyone is interested, and so I have a page to link to in the future.
Platform
Everything is done using MySQL, Perl, and R. These are all general computing tools, not the specific digital humanities or text processing ones that various people have contributed over the years. That's mostly because the number and size of files I'm dealing with are so large that I don't trust an existing program to handle them, and because the existing packages don't necessarily have implementations for the patterns of change over time I want as a historian. I feel bad about not using existing tools, because the collaboration and exchange of tools is one of the major selling points of the digital humanities right now, and something like Voyeur or MONK has a lot of features I wouldn't necessarily think to implement on my own. Maybe I'll find some way to get on board with all that later. First, a quick note on the programs:
Platform
Everything is done using MySQL, Perl, and R. These are all general computing tools, not the specific digital humanities or text processing ones that various people have contributed over the years. That's mostly because the number and size of files I'm dealing with are so large that I don't trust an existing program to handle them, and because the existing packages don't necessarily have implementations for the patterns of change over time I want as a historian. I feel bad about not using existing tools, because the collaboration and exchange of tools is one of the major selling points of the digital humanities right now, and something like Voyeur or MONK has a lot of features I wouldn't necessarily think to implement on my own. Maybe I'll find some way to get on board with all that later. First, a quick note on the programs:
Subscribe to:
Posts (Atom)