{kind=link}
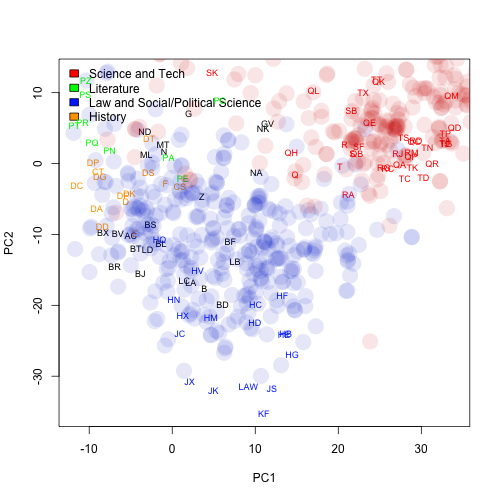
That's a little worse than I was hoping. Generally the books stay close to their term, but there is a lot of variation, and even a little bit of overlap. Can we do better? And what would that mean?
{kind=link}
First, let's review why we care about this at all. Categorizing and assigning texts is a big and vibrant field in information retrieval, and one that's starting to work around the temporal dimension. (Allen Riddell points to some good related sources, including digital history, in the comments). Humanists playing around with R aren't going to make substantive contributions to those algorithms, I'm afraid. What we can do, though, is see how the existing categorization algorithms might help a) provide insight into the categorizations we work with now, and b) help us find connections or documents that you can't simply search for. I'm not interested in tightening those circles for its own sake--I just want to see how we might use this data to learn things about books we have. There's thus some fairly low-hanging fruit (for example, what are the least coherent genres under the LC classification?) that I'll let be.
For this post, therefore, I'm just going to use a pretty simple form of categorization--Euclidean distance across the 10,000 words I'm using this week, using standard deviations from the mean term frequency for the word as the base metric. There are more subtle ways to do this--I'm not using the principal components, for example, that tell me which lexical information is a good predictor of genre ("hypothesis" vs. "premonition", say), and which isn't ("Williams" vs. "Smith", which can swing around wildly from book to book). But this should work as a first pass.
The vector space model lets us see which books a given book is closest to. Those blue dots above are only showing us closeness in two dimensions: if we include all the information that exists in the other 9,998 dimensions that using 10,000 words gets us, we can find the closest genres for the 350 psychology books in my main database as follows:
BF AC BJ BL LB BD B HM PN PS BX PZ Q HV PQ PR
212 25 19 17 14 13 9 7 5 5 4 4 4 2 2 2
QH BS BT BV CT DA E HN HQ PE PT
2 1 1 1 1 1 1 1 1 1 1
That is to say, about 2/3 are closer to BF than they are to any other genre. That's a lot better than the above diagram would indicate. The most common errors are to think a work is in AC (serials); the philosophy/religion classes BJ, BL, and BD; and LB, practice of education. Some of the mistakes aren't terrible: education and psychology are very hard to tell apart in this period, for example. And the oddballs are explicable, too. A lot of them seem to be because spiritualism is classed in with psychology. (I could just filter out everything will a call number above 1000 to get rid of them). Spiritualist tracts, depending on their bent, pop up as English history, in various religion classes, and elsewhere. I might well get better results in analyzing psychology by using a filter to eliminate texts closest to PZ, novels:
title year
1413 shadow world 1908
11698 After-death communications 1920
19354 Past and present with Mrs. Piper 1922
46370 Rachel comforted 1920
The other mistakes are more or less explicable, too. The book mistaken for E (US history) is The study of greatness in men; the one mistaken for PE, English language, is What handwriting indicates. There's a definite method to the madness. We'd certainly want to have a better algorithm overall, but the LCC classification limits our options. Forget a computer program--no humans not already familiar with the system would be able to determine just what goes into each subclass based purely on its name.
And anyway, as I said, our interest probably isn't in classifying: it's in finding interesting things for ourselves. So we can, for instance, find the 5 books in psychology that fit in the least well with the category:
title year
1108 sibylline oracles, books 3-5, by the Rev. H.N. Bate, M.A. 1918
5695 Methods and results of testing school children 1920
20024 Some remarkable passages in the life of Dr. George de Benneville 1890
46272 What handwriting indicates 1904
46370 Rachel comforted 1920
1108 sibylline oracles, books 3-5, by the Rev. H.N. Bate, M.A. 1918
5695 Methods and results of testing school children 1920
20024 Some remarkable passages in the life of Dr. George de Benneville 1890
46272 What handwriting indicates 1904
46370 Rachel comforted 1920
Some of these we saw before. Others are just strange--I had no idea that BF 1745-1779 was for "Oracles, Sibyls, and Divinations." Still, a lot of these books are just the kooks and quacks that anyone who's spent much time in the GAPE sees constantly.
What about the converse? We can see what books most perfectly mirror the overall language of the discipline by finding ones with the smallest distance:
What about the converse? We can see what books most perfectly mirror the overall language of the discipline by finding ones with the smallest distance:
title year
3750 Psychology 1915
20867 Psychology 1910
21558 Psychology 1892
25253 Psychology 1920
27473 The principles of psychology 1890
3750 Psychology 1915
20867 Psychology 1910
21558 Psychology 1892
25253 Psychology 1920
27473 The principles of psychology 1890
Why do those all look the same? The five most representative books of the BF class are five separate editions/volumes/revisions of William James's Principles of Psychology. That's rather nice. It might be a bit much to try to test to see if he's so perfect because he followed the field faithfully or because that text actually set the course of research, but there's something comforting about seeing we all read the book for the right reasons. (Joseph LeConte's textbook occupies the analogous place in geology, FTR).
More usefully, we can find books that match a given genre: the five psychology books, say, that most closely resemble the education class:
title bookid
18009 teacher's handbook of psychology teachershandbook00sull
24775 Mental growth and control. mentalgrowthcont00opperich
27473 The principles of psychology principlespsych12jamegoog
27607 Human conduct humanconducttext00pete
31767 Teaching to think teachingtothink00boragoog
18009 teacher's handbook of psychology teachershandbook00sull
24775 Mental growth and control. mentalgrowthcont00opperich
27473 The principles of psychology principlespsych12jamegoog
27607 Human conduct humanconducttext00pete
31767 Teaching to think teachingtothink00boragoog
Or the five novels written in 1912 that share the profile of HN, Social Reform and Social movements:
title year authors bookid
391 John Rawn 1912 OL1603793A johnrawnpromine00compgoog
10458 London Lavender 1912 OL113754A londonlavenderen00luca
12466 Along the King's highway 1912 OL4472940A alongkingshighwa00shooiala
12503 White ashes 1912 OL2390372A whiteashes00noblgoog
36466 King John of Jingalo 1912 OL42239A kingjohnjingalo00housgoog
46610 man's world 1912 OL2126668A amansworld00bullgoog
title year authors bookid
391 John Rawn 1912 OL1603793A johnrawnpromine00compgoog
10458 London Lavender 1912 OL113754A londonlavenderen00luca
12466 Along the King's highway 1912 OL4472940A alongkingshighwa00shooiala
12503 White ashes 1912 OL2390372A whiteashes00noblgoog
36466 King John of Jingalo 1912 OL42239A kingjohnjingalo00housgoog
46610 man's world 1912 OL2126668A amansworld00bullgoog
This is starting to get interesting. John Rawn, for example, carries a dedication to Woodrow Wilson, "one of the leaders in the third war of independence" and led to a times article in which he defended himself against charges of socialism; King John of Jingalo is a novel of court life; etc. White Ashes is about "the romance of fire insurance:" a review that says "Big business interests enter into the plot; and while characters subordinate to theme, there is sufficient love interest to relieve the strain of insurance talk and transactions." These are good ways of turning up cultural ephemera that are typical of longer-term trends but might have been lost in the meantime.
If Ted Underwood is right that search is the killer app of text mining, there's still an enormous amount of work that could be done to allow topical, rather than keyword, search. Historians love to and need to find books that cross the same boundaries as their unique research topics. At least at Princeton, that seems to be happening more and more. (Probably because of Google Books, in part). This doesn't need to be limited to genre, incidentally--we could find the book published in Pittsburgh that most resembles books using "evolution" and "society" a lot, or list the books of Henry James by how closely they mirror his brother's overall style. If this were easy to do, historians would find it an incredibly useful tool for filling in gaps in their research. Keyword search is only one kind of search, but it's the only one the vast majority of historians have access to.
So why can't you go on Amazon or Google and do these searches? Two basic reasons, I think:
If Ted Underwood is right that search is the killer app of text mining, there's still an enormous amount of work that could be done to allow topical, rather than keyword, search. Historians love to and need to find books that cross the same boundaries as their unique research topics. At least at Princeton, that seems to be happening more and more. (Probably because of Google Books, in part). This doesn't need to be limited to genre, incidentally--we could find the book published in Pittsburgh that most resembles books using "evolution" and "society" a lot, or list the books of Henry James by how closely they mirror his brother's overall style. If this were easy to do, historians would find it an incredibly useful tool for filling in gaps in their research. Keyword search is only one kind of search, but it's the only one the vast majority of historians have access to.
So why can't you go on Amazon or Google and do these searches? Two basic reasons, I think:
- Search engines don't work that way, and the ways indexes are constructed on books right now, it would take massive computing power to do these searches. (I'm getting closer to posting my long-delayed thoughts on indexing, I promise…). Keyword search is useful across all kinds of fields: genre-cluster search has a much tinier audience.
- Just as important: the interface would be clumsy, and that's not how Cloud Computing likes things to look. From the Chronicling America newspapers project to Google Books, we seem to have come to an agreement that the way for scholars to interact with databases is through opaque web forms. It makes the initial stages of contact much easier, but generates nowhere near the possibilities of SQL queries. Nor does it let you interact with other data sources. If my Zotero library were slightly better tagged, for instance, I would be able to find books in my 15,000-book psychology/education dataset that resembled the various portions of it or the portions as a whole. But I can't do that on Jstor articles or ProQuest newspapers, because aside from archive.org, basically of our book data is trapped inside the copyright black hole because of metadata, scanning rights, or pure indifference.
Speaking as a literary historian, I can immediately see the utility of a tool that would let me find "the novels that most closely echo discourse X in period Y." That would be extremely valuable.
ReplyDeleteI'm trying to build something similar, although I'm conceiving it as a tool that finds volumes that echo a trend (i.e., are early outliers in it), rather than echoing a synchronically-defined discourse. But for most purposes I think the discourse-matching concept will be more useful, and its uses will also be easier for scholars to grasp.
" It would be tricky, but there's still some room for a different attitude towards how digital libraries can have something better than digital card catalogs."
ReplyDeleteYou might want to check out Clifford Lynch's efforts to refocus the "open access" debate on computational access to scholarly literature, e.g. http://www.cni.org/staff/cliffpubs/OpenComputation.htm
Great work Ben. I've been working on similar techniques for journalism at the Associated Press, where we get huge document dumps pretty much weekly. I've been using multi-dimensional scaling instead of PCA, because it can better represent the clustering structure than simply throwing out the rest of the dimensional data. But it's still based on TF-IDF document vectors so the principle is the same. I've even found pre-existing categories to plot against the layout. So I think you'll definitely be interested in my talk at the computer-assisted reporting conference in Raleigh last week.
ReplyDelete"Digital humanities" and "computational journalism" have a lot of common ground, and I'm happy to see someone thinking similarly in another field.
- Jonathan
Jonathan,
ReplyDeleteThanks for the link--I read about overview a while ago, and it would definitely have applications for historians looking at massive archival sources as well (once we figure out how to get them digitized, of course…) Really exciting stuff.
Yeah, it definitely turns out it's necessary to use all the vector-space data, not just the principal components. It's not bad, though, once you do. For visualizing, I take it you're using some type of force-directed placement algorithm to arrange the documents in 2-D? That seems like the right way to go for visualization; it works much better when I've tried it.