A couple notes for the technically inclined:
1. the years are pulled from field 260c (or if that doesn't exist or is unparseable, from field 008). Years in non-western calendars are often not converted correctly.
2. There are obviously books from before 1770, but they aren't included.
3. By "books", I mean items in the LC's recently-released retrospective (to 2014) "Books all" MARC files. http://www.loc.gov/cds/products/product.php?productID=5. Not the serial, map, etc. files: the total number is just over 10 million items.

my_annotate = function(lab,label,width=40,col="#EEEEEE",...) {
annotate(geom="text",...,label=str_wrap(label,width = width),family="OpenSans-CondensedLight", lineheight=0.75,size=3.5,col=col)
}
plot = data %>% filter(marc_record_created_year < 2017, marc_record_created_year>1965, record_date > 1700, record_date < 2017) %>%
ggplot() +
geom_raster() +
aes(x=record_date,y=marc_record_created_year, fill=TextCount) +
scale_y_continuous(position=c("right"),expand=c(0,0)) +
scale_x_continuous(position=c("bottom"),breaks=seq(1770,2020,by=10),limits=c(1770,2025),expand = c(0,0)) +
scale_fill_gradientn("Number\nof books\ncataloged", trans="log10",
colors = rev(magma(5)),breaks=outer(c(1,2,5,10),c(1,10,100,1000,10000),"*") %>% as.vector %>% unique) +
theme_bw() +
theme(legend.key.height = unit(1,"in"),
plot.title = element_text(size=22)
) +
annotate("segment",y=1968,yend=2014,x=1968,xend=2014,lwd=1.5,color="white",lty=2) +
labs(x="Year of book",y="Year of MARC record",title="MARC cataloging at the Library of Congress",
subtitle="A brief visual history comparing the year that records were created (left to right) with the year that the books described in them were published" %>% str_wrap) +
coord_flip() +
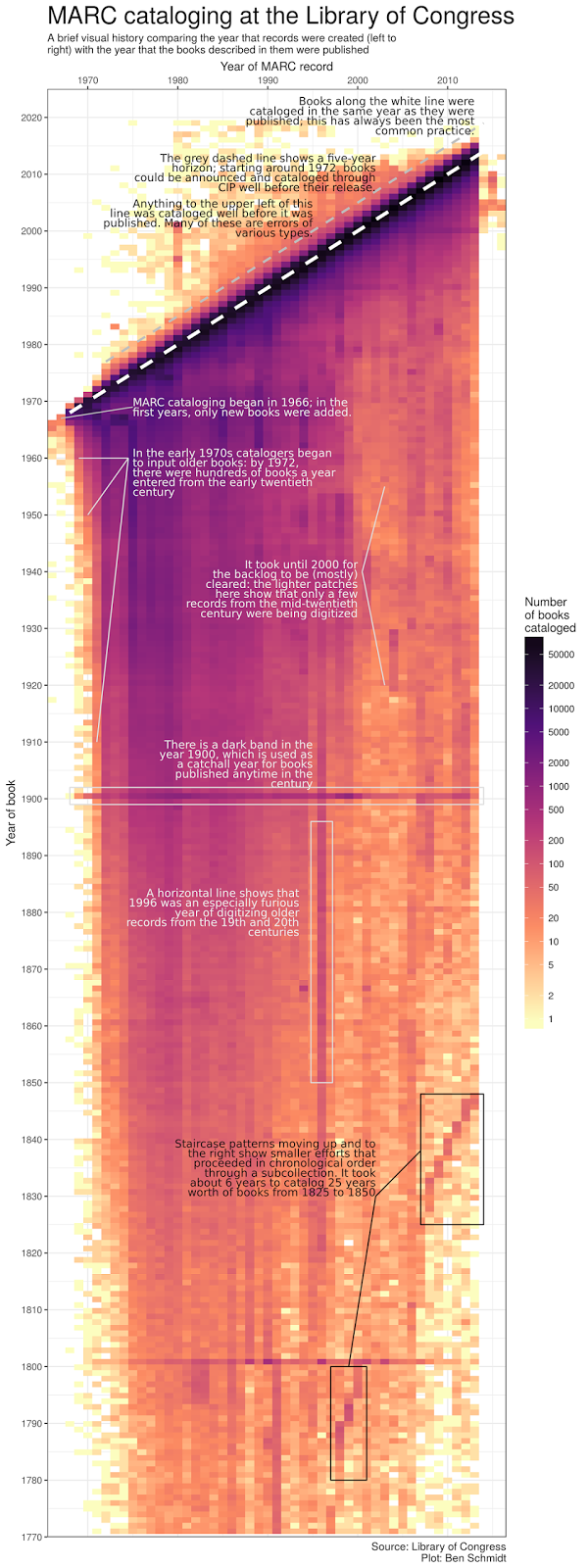
my_annotate(y=2013,x=2017,label="Books along the dashed line were cataloged in the same year as they were published; this has always been the most common practice",hjust=1,vjust=0,col="black") +
my_annotate(y=1995,x=1999,label="Anything to the upper left of this line was (supposedly) cataloged before it was published: this is impossible! These are all errors of some type.",hjust=1,vjust=0,col="black") +
my_annotate(y=1975,x=1969,label="MARC cataloging began in 1968; in the first years, only new books were added.",hjust=0,vjust=0.5,width=40,col="#EEEEEE") +
annotate(geom="segment",x=1967,xend=1969,y=1967,yend=1975,col="grey") +
my_annotate(y=1975,x=1960,label="In the early 1970s catalogers began to input older books: by 1972, there were hundreds of books a year entered from the early twentieth century",hjust=0,vjust=0.8,width=35,col="#EEEEEE") +
annotate(geom="segment",x=1910,xend=1960,y=1971,yend=1974.5,col="#DDDDDD") +
annotate(geom="segment",x=1950,xend=1960,y=1970,yend=1974.5,col="#DDDDDD") +
annotate(geom="segment",x=1960,xend=1960,y=1969,yend=1974.5,col="#DDDDDD") +
my_annotate(y=2000,x=1940,label="It took until 2000 for the backlog to be (mostly) cleared: the lighter patches here show that only a few records from the mid-twentieth century were being digitized",hjust=1,vjust=0.8,width=30,col="#EEEEEE") +
annotate(geom="segment",x=1940,xend=1955,yend=2003,y=2000.5,col="#DDDDDD") +
annotate(geom="segment",x=1940,xend=1920,yend=2003,y=2000.5,col="#DDDDDD") +
my_annotate(y=1995,x=1902,label="There is a dark band in the year 1900, which is used as a catchall year for books published anytime in the century",hjust=1,vjust=0,width=30) +
annotate("rect",ymin=1968, ymax=2014, xmin=1899,xmax=1902,fill=NA,color="#DDDDDD",alpha=.5) +
annotate("rect",ymin=1994.8, ymax=1997.2, xmin=1850,xmax=1896,fill=NA,color="#DDDDDD",alpha=.5) +
my_annotate(y=1993.5,x=1880,label="A horizontal line shows that 1996 was an especially furious year of digitizing older records from the 19th and 20th centuries",hjust=1,vjust=0.5,width=30) +
my_annotate(y=2002,x=1830,label="Staircase patterns moving up and to the right show smaller efforts that proceeded in chronological order through a subcollection. It took about 6 years to catalog 25 years worth of books from 1825 to 1850",hjust=1,vjust=0,width=35,col="#111111") +
annotate(geom="segment",x=1838,xend=1830,yend=2002,y=2007) +
annotate(geom="segment",x=1800,xend=1830,yend=2002,y=1999) +
annotate("rect",ymin=2007,ymax=2014,xmin=1848,xmax=1825,fill=NA,color="black",alpha=.5) +
annotate("rect",ymin=1997,ymax=2001,xmin=1780,xmax=1800,fill=NA,color="black",alpha=.5)
ggsave(plot,device="png",filename="~/Pictures/MARC.png",width=7.5,height=20)
Cataloged before publication...actually these indicate MARC (pre-)records added by LoC that reflect information from pre-publication copies deposited at LoC. See this wikipedia article for the full low-down (https://en.wikipedia.org/wiki/Cataloging_in_Publication). You might also want to actually check with a cataloger before you publish your (wrong) conclusions. #domainexpertisestillking
ReplyDeleteI didn't say they weren't my errors! That's why I put this online before actually "publishing." You're right that there are a lot of records for the horizon a year or two out, and I will change the chart to reflect this.
DeleteBut you're wrong to imply there aren't many cases of severely misdated records in the area the visualization pulls out. Spot-checking books ten years off or more shows a lot of mistakes, as often on the publication date as the year.
There's also a lot of Serbian books with MARC record years in the 2020s. Any idea what that is?
MariaDB [LOC]> SELECT first_author_name,title,marc_record_created_year, record_date FROM catalog WHERE marc_record_created_year > 2017 ORDER BY RAND() LIMIT 10;
+------------------------------------+-------------------------------------------------------------------------------+--------------------------+-------------+
| first_author_name | title | marc_record_created_year | record_date |
+------------------------------------+-------------------------------------------------------------------------------+--------------------------+-------------+
| Jovanović Danilov, Dragan, 1960- | Homer predgrađa / | 2024 | 2003 |
| Simonović, Saša. | Kosovo i jedna ljubavna priča / | 2027 | 2007 |
| Pavelić, Dragan, 1946- | Proljeće u Karolinentalu / | 2019 | 2009 |
| Gledić, Vojislav. | Nikola Tesla : život idelo / | 2018 | 2007 |
| Kusturica, Nazif, 1928- | Doticaji i suočenja. | 2029 | 2011 |
| Šuković, Mijat. | Istorija zakonodavstva Crne Gore, 1796-1916 / | 2018 | 2007 |
| Pejić, Radmilo, 1937- | Plava fontana : roman u maniru trilera / | 2024 | 2004 |
| | Modriča vodič kroz grad i vrijeme : modričke ulice i trgovi / | 2027 | 2011 |
| Panić- Maraš, Jelena. | Grad i strast : naturalistički elementi u srpskom modernističkom romanu / | 2027 | 2009 |
| Suljić-Boškailo, Bisera, 1965- | Tomas Man na svojim izvorima / | 2025 | 2009 |
+------------------------------------+-------------------------------------------------------------------------------+--------------------------+-------------+
A further complication is that a lot of MARC records seem to list dates in Hebrew or Buddhist-era years. That's less of a big deal in this part of the chart.
Still, that would explain the high density of books just over the dashed white line—but isn't it remarkable that many books published in 2000 were apparently catalogued 20 years in advance?
DeleteP.S. I'm not OP.
The Serbian books with MARC record years in the 2020s were probably the result of entering the date incorrectly in the 008. For instance, Proljeće u Karolinentalu has "190410" in the 008. It probably should have been "100419" (yymmdd). The 010 is 2010418152, indicating it was cataloged in 2010, but the 035 indicates the record came from a university press in Sarajevo.
DeleteSorry to sound like a grumpy cat but I wouldn't assume that those dates are wrong unless you can find someone who can authoritatively state that they are. That said, there are sure to be lots of things that look suspicious and might be outliers. But it's not easy to just say something is wrong because frequently we know things will be published at some (unfixed) point in the future (case in point - George RR Martin's Winds of Winter novel). Looking at the area above your curve and noting that in the 1980s there seem to be records for the 2010s (or in the example in your reply), I'd say that not only is it possible, it's normal, because of CIP. The more interesting thing is how it begins to contract and intersect as we move through time. This may be for several reasons.
ReplyDelete1) You might have an arbitrary cut-off point for the visualization and, the contraction is an artifact of that.
2) The practice of CIP might be ending.
3) The lead time between when a publisher provides CIP data and the actual publication date of the item is getting smaller.
4) Both 2 and 3 are occurring.
I'd be inclined to think that it's #4 but I'm surprised there isn't a noticable change in the curve when ebooks are introduced but it possible that there might be no ebooks (or marc records for such) in your dataset. But I also don't want to discount #1.
I'm also suspicious of the 1900 line. As we've explained to you in the past, MARC records have a number of places where the reliability or contextual meaning for that date is recorded. Always recording it as 1900 is misleading because sometimes it means "20th century" but it could also mean any of "sometime between 1900 and 2000", "sometime between 1900 and 1910", "circa 1900", and similar ranges or estimated dates. The dark color is actually indicating the semantic overlap among particular values. The MARC record should have additional information which is typically distributed across several MARC fields to help disambiguate it but additional parsing and some assembly would be required to make sense of "1900". Development of a semantic classifier might be helpful here.
As for your example in your reply, I'm not sure about your Serbian MARC records, but as it looks systematic, i.e., there are alot of them cataloged with the claim that the record is from the future, I'd suggest it might be an artifact of something at the policy level and that without contacting the source library or any of the catalogers involved with making the records we can't tell if it is an error of it simply violates our expectations for what the value of that data element should be.
Lost a longer response while updating the chart, but a couple quick points:
Delete1. Thanks for sticking with me.
2. This is not the Hathi catalog, it's the Library of Congress catalog, (from your comment I suspect your Hathi?) so it my expectation is that it will fewer accordances for distinctive local practices.
3. I take your point that we can't be *sure* of errors without contacting the source library: but in many of these cases I think it's safe to presume, and it's important for any researchers using records like this to go in with the baked-in assumption that there are substantial numbers of bad years in there, even if we don't precisely which are which.
4. One of the reasons I'm really suspicious of fifteen-year CIP lead-time books you describe in the 1980s is that it's not just that there are books published on long time horizon; it's that fifteen-year horizon books are often just about more common than (say) 8 year horizon books. (Things are particularly bad in 1980, where something with Arabic-language texts seems to be going wrong). I find it really suspicious that there's a straightforward decay for the first few years (one-year lead times are more common than two-year, etc.) but that afterwards some other dynamic takes over.
There was a concerted retrospective conversion effort that took LC's card catalog and converted it to MARC at a facility in Aberdeen Scotland. It was called REMARC. You can find some data
ReplyDeletehttp://dx.doi.org/10.1108/eb046867
http://dx.doi.org/10.1300/J124v02n03_02
and undoubtedly others. This was in the mid-1980's. I wonder if this fits anywhere into your timeline. I don't think it explains the 1996 band, but I also do not know exactly when LoC integrated this data into its own catalog. Many other libraries used this data as it was sold as a service. Would love to hear if you find evidence of this.
Interesting. Yeah, I'm turning up a number of sources here; I found this 1987 article (https://www.jstor.org/stable/23507431?seq=2#page_scan_tab_contents) helpful in understanding this from on the LOC side of things, which is the processing the REMARC records created by Carrollton Press into "PREMARC" records at LOC relied on format based codes that frequently became misaligned or included transcription errors. It looks like 1980-1990 might be the peak of this kind of activity.
DeleteThat article says 4.6 million records were coded, which is a lot (LOC just released 25 million records; I'm looking only at books, of which there are ~ 10 million.)
One upshot is that it may be hard to tell REMARC/PREMARC encoded entries from those internally created at LC, because the actual MARC creation was done at LC on files from Scotland. I thought that maybe MARC field 040c (which ascribes transcription of an original record) would have this, but they appear to just be under one of the LOC codes.
I just spot-checked 1 million MARC records and most of those that have a transciber list it as straight DLC (Library of Congress), with significantly smaller input from other places.
For the record, those are:
[(u'DLC', 579599),
('no field c', 256149),
(u'DLC-R', 32709),
(u'DLC-RdDLC', 7129),
(u'CU', 5257),
(u'ICU', 4889),
(u'BTCTA', 4599),
(u'MH', 3705),
(u'WaU', 3493),
(u'ItFiC', 2608)]
Ah, more information here: apparently MARC 042 in the LC records specifically identifies premarc files. http://www.loc.gov/cds/notices/premarc.html. So it should actually be easy to separate out the PREMARC story in something like this, though it would take a more complicated visual vocabulary or a specific question going in.
DeleteThat only applies to that particular project. 042 has been in use for ages to list acronyms applying to lots of other projects, which have include LC staff or are LC projects. LC has some of the most senior luminaries in our field with incredible historical knowledge of practices over time and over content, and they might be able to better explain premarc and the other projects better in person.
DeleteYou will get no argument from me there. I was down at the LC just this week talking to LC staff and looking at archival materials and will continue to do so.
DeleteThere are 042 fields indicating premarc in (maybe) 5% of the million quasi-random records I checked. It may be that some premarc tags were purged after inspection, as described in the above link; or that they never made it over.
For the Serbian books above: the record date is actually the correct year of publication (according the online catalogue maintained by the National Library of Serbia), if it helps for the discussion.
ReplyDeleteBogdan
Yeah, looking a little more at these it appears that the first 6 digits of field 008 are entered in the format 'ddmmyy' instead of 'yymmdd'; if you make that twist, all the books were actually published between 2008 and 2011, and entered (by the LC itself, not shown in the field 008s below) between March and November 2011.
Delete=008 250511s2008\\\\bn\a\\\\\b\\\\000\0\srp\d
=008 250511s2010\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 250511s2007\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 270611s2010\\\\bn\a\\\\\b\\\\000\0\hrv\\
=008 250511s2010\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 221111s2011\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 280311s2009\\\\bn\\\\\\\b\\\\000\0\bos\\
=008 290411s2009\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 270611s2011\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 250511s2008\\\\bn\a\\\\\b\\\\000\0\bos\\
=008 250511s2006\\\\bn\\\\\\\\\\\\000\1\bos\\
=008 270611s2010\\\\bn\ah\\\\\\\\\001\0\hrv\\
=008 250511s2010\\\\bn\a\\\\\b\\\\000\0dbos\\
=008 250511s2010\\\\be\\\\\\\\\\\\000\1\bos\\
=008 250511s2011\\\\bn\c\\\\\b\\\\001\0\bos\c
=008 231111s2010\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 250511s2011\\\\bn\c\\\\\\\\\\000\0\bos\\
=008 280311s2010\\\\bn\a\\\\\b\\\\000\0\bos\\
=008 221111s2011\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 250511s2008\\\\bn\\\\\\\\\\\\000\0\bos\c
=008 221111s2010\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 290411s2010\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 290411s2010\\\\bn\a\\\\\\\\\\000\0abos\\
=008 280311s2011\\\\bn\\\\\\\b\\\\000\0\bos\\
=008 250511s2011\\\\bn\\\\\\\b\\\\000\0\bos\\
=008 231111s2011\\\\bn\\\\\\\b\\\\000\0\srp\\
=008 250511s2011\\\\bn\a\\\\\b\\\\000\0\bos\\
=008 221111s2010\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 300311s2009\\\\bn\\\\\\\b\\\\001\0\eng\\
=008 280311s2008\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\srpo\
=008 250511s2010\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 231111s2011\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 231111s2010\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 220211s2011\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 280311s2009\\\\bn\a\\\\\\\\\\000\0dbos\c
=008 250511m20059999bn\\\\\\\b\\\\000\0cbos\\
=008 250511s2011\\\\bn\\\\\\\b\\\\001\0\bos\\
=008 221111s2011\\\\bn\a\\\\\\\\\\000\0\srp\\
=008 250511s2009\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 250511s2010\\\\bn\\\\\\\b\\\\000\0\bos\\
=008 280311s2011\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 250511s2010\\\\bn\\\\\\\b\\\\000\0\bos\\
=008 280311s2011\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 250511s2008\\\\bn\ab\\\\b\\\\000\0dbos\\
=008 280311s2010\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 250511s2010\\\\bn\c\\\\\b\\\\000\0\hrv\\
=008 250511s2007\\\\bn\\\\\\\\\\\\000\j\bos\\
=008 250511m20099999bn\a\\\\\b\\\\000\0\bos\\
=008 290411s2009\\\\bn\\\\\\\\\\\\000\0\bos\\
=008 280311s2010\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 250511s2010\\\\bn\\\\\\\\\\\\000\0\srp\\
=008 250511s2011\\\\bn\a\\\\\\\\\\000\0\bos\\
=008 250511s2011\\\\be\\\\\\\\\\\\000\1\bos\\
=008 290411s2007\\\\bn\c\\\\\\\\\\000\0\bos\\
=008 280311s2011\\\\bn\\\\\\\\\\\\000\0\bos\\
Data mining MARC records isn't gong to help you understand the books and their classifications. Visualizing some dates also won't help you get the history of how "digital card catalogs" (drawers full of digital 3x5 paper cards?) were created, either. You missed out on all the changes in date coding practice, subjective current practices and subjective historical applicationS of work that most of us have spent years and money on Masters degrees, and years of practice, understanding ourselves. DH is so much more than collecting matching data points and visualizing them!
ReplyDeleteI did say "brief" for a reason! Of course you're right that the 100 words (or whatever it is) on this chart don't describing everything interesting about MARC. And they certainly don't obviate all the expert knowledge that goes into cataloging! I hope no one would think the opposite.
DeleteThat said, I do think that MARC records are an important historical record that have a lot to offer for understanding library books and their classifications, and that visualization and data mining can be helpful in that.
You may need to add some wording for your definition of "classifications". In the library cataloging world, classification is specifically used for the selection of call numbers. Also, not MARC-based. You are also likely collecting a lot of MARC data For non-book formats due to coding changes during the span of format integration, and when UNIMARC, CANMARC, and USMARC were combined and altered/clarified.
DeleteYour post is going viral in library personnel social media, so we all read your words and your data in the frame of our knowledge, training, and experience. If you intend a different understanding, you will need to clarify your definition of what our field considers highly technical terminology with specific meanings.
Yeah, I can see why it would be confusing that I say classification and then don't mention them; but I do mean "classification" in the technical sense. This year stuff is preparatory for actually working with the LC Classification numbers in the book MARC records (and the MARC-formatted LC classification itself, http://www.loc.gov/cds/products/product.php?productID=14); since classification numbers are passed on through MARC records, I'm trying to understand better the provenance of the MARC here.
DeleteI think I am also using "books" in a somewhat technical sense: those items in the Library of Congress's retrospect MARC books file, and not the serials file, maps file, etc. If you think that a lot of other format items have migrated into the LC catalog, I would love to know a little more.
But yeah, gonna edit to make this clearer up top...
DeleteAccess to the current classification system can be done online but requires a subscription. It is also available in print if you have access. Older guidelines for the various MARC implementations are also available in print so you could get a sense of its application before format integration. Dates have only been appended to LC call numbers in recent years, so that may not be helpful for what you ate trying to achieve. A wide variety of agencies and organizations took part in helping get LC's descriptive data in MARC form. Some of that work was part of Title II grants. And LC call numbers may live outside of bibliographic MARC records in certain cases. MARC has different systems itself, and call numbers in the software that LC uses may be actually found in MARC Holdings data instead depending on how they use the Voyager system.
DeleteOh I linked to the pay page for the LCC. This is what's so exciting right now: LC just released a reasonably new version (2014) of the full LC classification. Link at the bottom of the page. http://www.loc.gov/cds/products/marcDist.php.
DeleteAlmost all (99.8%) the books have an LC call number in the MARC records distributed here, fortunately.
Well good luck anyway. Many of us will be watching, and hopefully you find the info you are looking for in this project.
Delete"A horizontal line shows that 1996..."
ReplyDeleteyou mean "vertical"?